urllib爬虫实战之爬取笔趣阁小说
前言
上一节我们介绍了urllib这个基本库,它的内容还是蛮多的,要想熟练掌握爬虫,必须配合实战进行巩固。一开始小伙伴们可能会觉得无从下手,特别是解析响应内容这一步。这一次,作者将会从小白的角度,讲述如何对网页进行爬取、解析。
环境
运行平台: Windows
Python版本: Python 3.x
IDE: Pycharm
BeautifulSoup简介
- BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据。BeautifulSoup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
解析器
BeautifulSoup 在解析的时候实际上是依赖于解析器的,它除了支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器比如 LXML 。 Beautiful方法有两个参数,第一个参数传入待解析的文本,第二个参数指定解析器,如果我们想要使用 LXML 这个解析器,在初始化 BeautifulSoup 的时候指定 lxml 即可,如下:

好了,简单介绍了BeautifulSoup,我们快点进入今天的实战环节吧~
实战
背景介绍:笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说。
PS:本实例仅为交流学习,支持耳根大大,请上起点中文网订阅。
预备知识: 本文提及的代码并不复杂,如果对BeautifulSoup想要更加了解,可以去官方文档进行翻阅
BeautifulSoup环境搭建:
- pip install bs4
- 导入使用 – from bs4 import BeautifulSoup
获取内容
① 打开url链接,按F12或者右键- 检查 进入开发者工具

② 在开发者工具中,捕获我们要找到的请求条目信息
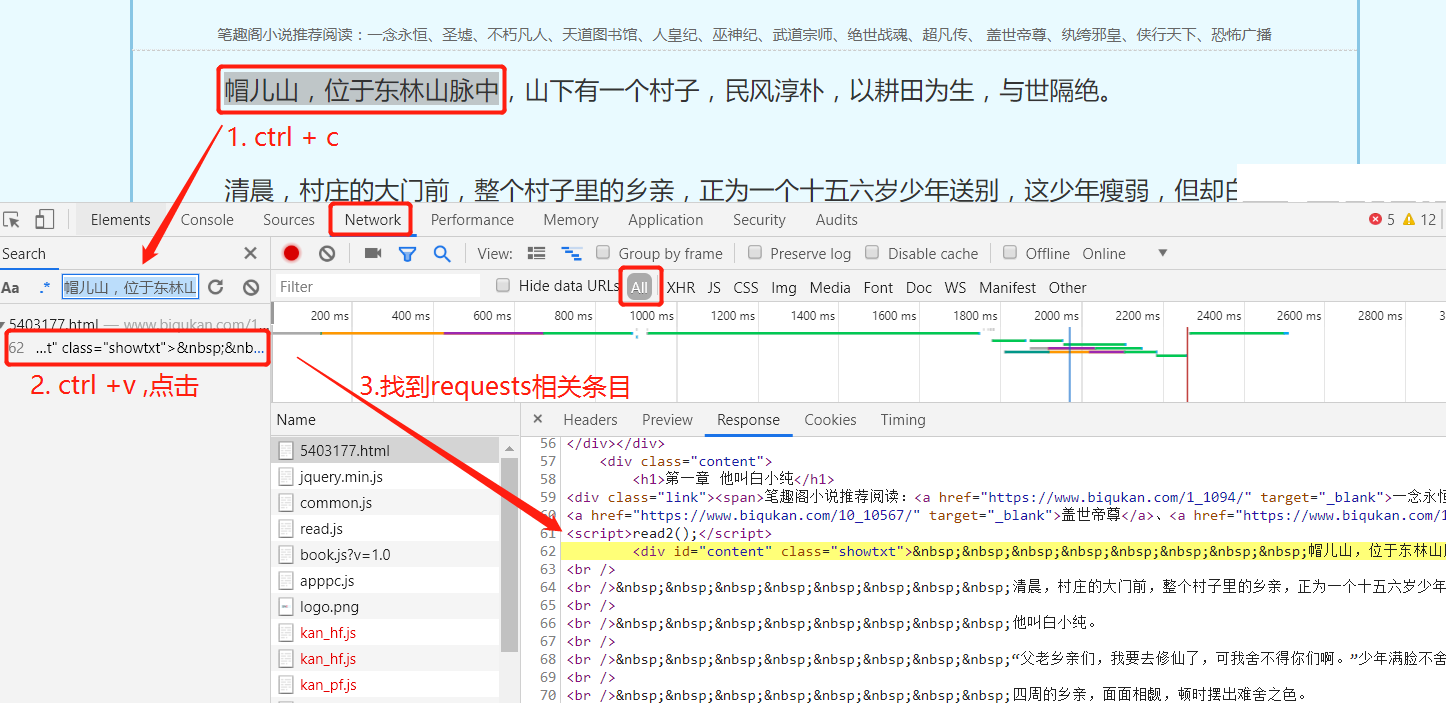
- 将正文中部分内容进行复制
- 在开发者工具中,使用 ctrl + f 进入全局搜索框,将复制内容进行粘贴
- 然后会在下方得到条目信息,点击,页面会跳转到加载正文的请求响应条目中。
- 分析发现,正文部分存储在 id 为 content 和 class 为 showtxt 的 div 中。这就是我们解析网页得到的重要信息啦
③ 构造url请求
有了上面的信息还不够,现在的网站都有了反爬能力,我们需要模拟一条正常从浏览器中发出的url请求链接。
例如: User-Agent(浏览器标识)、Cookies(标识客户端身份的“钥匙”)、referer等等字段
那么,这些包含在请求头的字段信息,我们应该如何构造这些字段信息呢? 还是开发者工具,点击Headers,就可以看到Request-Response条目明细。

④ 发出请求: 有了字段的详细内容,我们就可以编写出请求网页的代码…
1 | import urllib.request |
⑤ 获得相应内容:运行,得到内容如下:
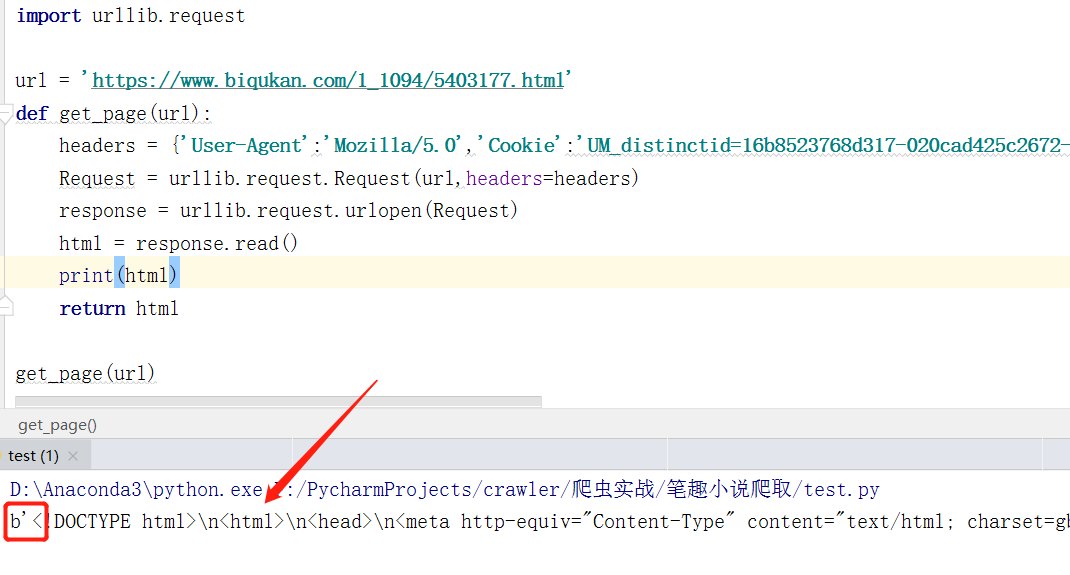
发现是一个二进制流的数据,因此得知,我们在解析时,需要编码
解析响应数据
接下来,我们就可以使用BeautifulSoup进行解析
1 | def parser_page(html): |
运行….代码结果如图:
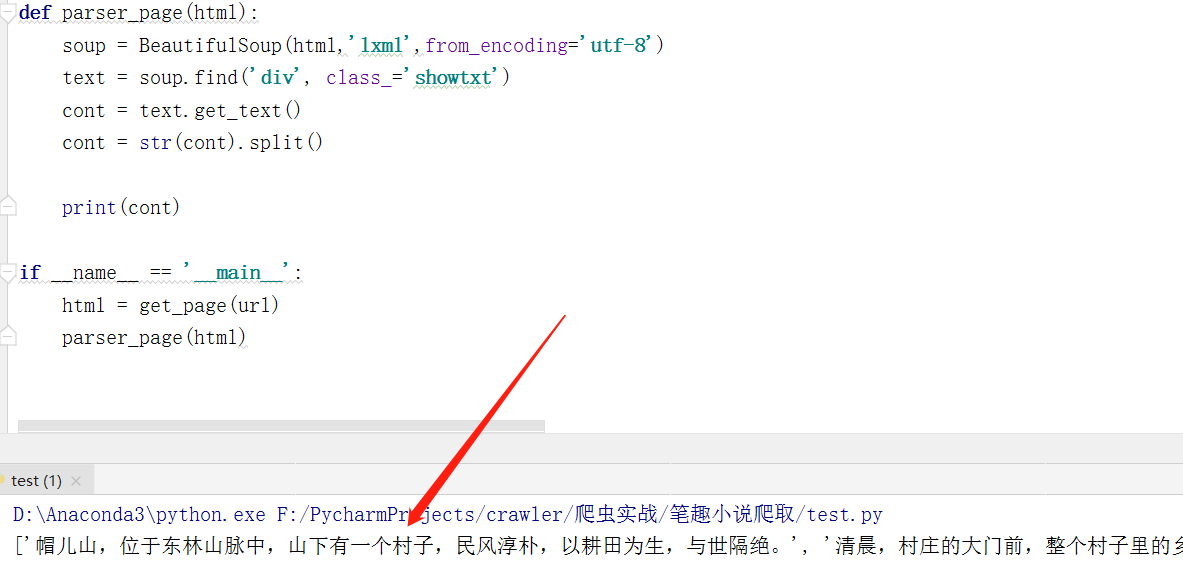
拿到小说数据! 到这里,不少同学露出这样的微笑,哈哈哈

永久存储数据:
我们这里使用最简单的方式,存储写入本地文件
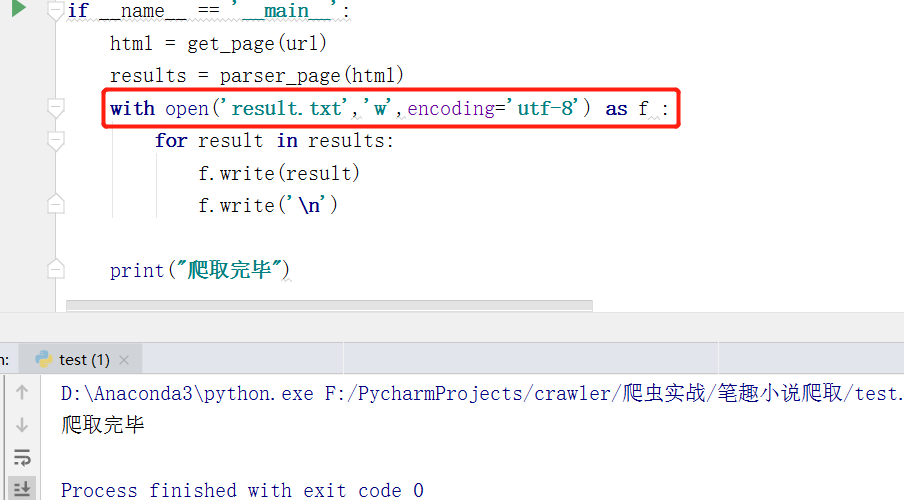
打开result.txt文件,内容如下:

写在最后
本次我们实战项目就告一段落啦,最后再为大家做一次梳理总结。
- 观察网页信息,获取相应内容
- 构造get请求,拿到响应内容
- 用解析库对相应内容进行解析
- 写入文件
全文代码如下:
1 | import urllib.request |
耗费一上午时间,终于把这篇文章给赶出来了~
爬虫Day系列会持续更新,让我们共同期待吧!
