Urllib介绍
在 Python2 版本中,有 Urllib 和 Urlib2 两个库可以用来实现Request的发送。而在 Python3 中,已经不存在
Urllib2 这个库了,统一为 Urllib。
urllib分为四个模块:
- 第一个模块是request,它是最基本的HTTP请求模块,我们可以用它模拟发送请求,就像在浏览器手动输入网址然后敲击回车一样,只需要给库方法传入URL,以及额外的参数,就可以模拟实现整个过程了。
- 第二个模块是error,即异常处理,如果出现请求错误,我们可以捕获这个异常,然后进行异常的处理,保证程序的稳定性
- 第三个模块是paser,它是一个工具模块,提供了许多URL处理方法,比如拆分、解析、合并等操作
- 第四个模块是robotparser,主要是用来识别网站的robots.txt的(反爬虫的文本说明)
下面我就对以上模块进行重点讲解~

request模块
1.urlopen方法:
我们从上面知道,request是HTTP请求模块,那么具体的请求方法是什么呢?没错,正是urlopen!
1 | urlopen的API: |
我们通过urllib.request.urlopen(“url链接”)就可以请求到网页,如下图所示

这个请求的返回结果response,就是服务器响应内容。紧接着,我们可以调用这个对象包含的方法对返回的内容进行处理。

response.read()读取响应内容,它是HTML纯文本,它以字节流的形式返回的,于是要解码成utf-8,得到字符串。
respon.status 返回网页的状态码,如果网页的状态码是200,则表示正常。
利用以上最基本的 urlopen() 方法,我们可以完成最基本的简单网页的 GET 请求抓取。
2.data参数
data 参数是可选的,另外如果传递了这个 data 参数,它的请求方式就不再是 GET 方式请求,而是 POST。我们就可以使传递data参数,完成模拟登陆等类似功能… 具体如何模拟from表单,后文的urllib.parser会讲解
3. timeout参数
timeout 参数可以设置超时时间,单位为秒,意思就是如果请求超出了设置的这个时间还没有得到响应,就会抛出异常,如果不指定,就会使用全局默认时间。
我们可以通过设置timeout值,从而缩短超时时间。或者是让程序不会一直处于阻塞状态(我们知道,客户端和服务器的交互是一个同步过程,我们可以利用timeout参数,以及异常处理来完成非阻塞的效果,以及让程序不会异常终止,让程序更加稳定)
4.构建Request对象
我们知道利用 urlopen() 方法可以实现最基本请求的发起,但这几个简单的参数并不足以构建一个完整的请求,如果请求中需要加入 Headers 等信息,我们就可以利用更强大的 Request 类来构建一个请求。比如可以构建请求链接的浏览器标识等等
下面是正常的urlopen请求和使用Request构建URL的代码举例:
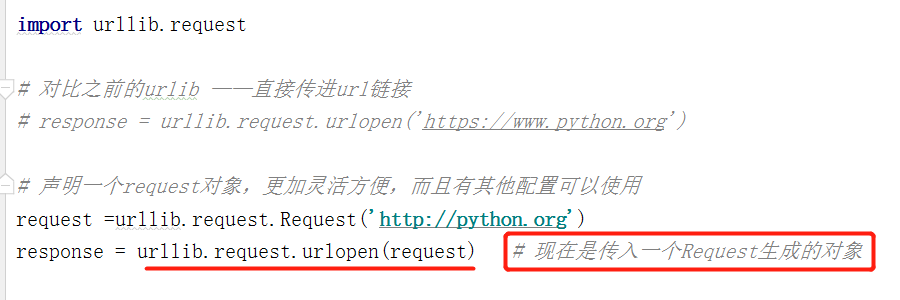
可以发现,我们依然是用 urlopen() 方法来发送这个请求,只不过这次 urlopen() 方法的参数不再是一个 URL,而是一个 Request 类型的对象,这样的好处是:
- 一方面我们可以将请求独立成一个对象,另一方面可配置参数更加丰富和灵活(将参数全部加到Ruquest对象中作为一个整体发送)
Request配置举例
之前我们说到过,可以构建url链接,比如关键字查询、模拟登陆。还可以模拟浏览器标识,让爬虫更像是一个人为发出的请求信息。具体内容如下:

headers 参数是一个字典,这个就是 Request Headers 了,你可以在构造 Request 时通过 headers 参数直接构造,也可以通过调用 Request 实例的 add_header() 方法来添加。
data就是我们发出的数据了,他会以表单形式向服务器发出
method是方法的意思,我们可以指定method来声明这是一个什么类型的请求方法。
Error模块
前文我们了解了 Request 的发送过程,但是在网络情况不好、被反爬的情况下,出现了异常怎么办呢?这时如果我们不处理这些异常,程序很可能报错而终止运行,所以异常处理还是十分有必要的。
Urllib 的 error 模块定义了由request 模块产生的异常。如果出现了问题,request 模块便会抛出error 模块中定义的异常
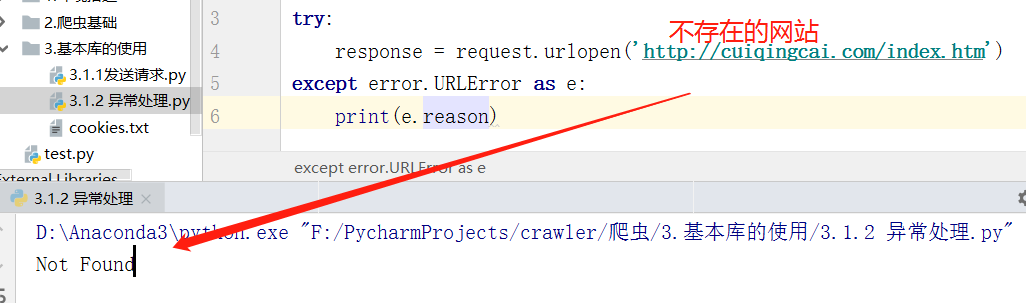
1.URLError
URLError 类来自 Urllib 库的 error 模块,它继承自 OSError 类,是 error 异常模块的基类,由 request 模块生的异常都可以通过捕获这个类来处理。它具有一个属性 reason,即返回错误的原因。
2.HTTPError
它是 URLError 的子类,专门用来处理 HTTP 请求错误,比如认证请求失败等等。
它有三个属性。
- code,返回 HTTP Status Code,即状态码,比如 404 网页不存在,500 服务器内部错误等等。
- reason,同父类URLError一样,返回错误的原因。(有时候 reason 属性返回的不一定是字符串,也可能是一个对象—可以用 isinstance() 方法来判断它的类型,做出更详细的异常判断。)
- headers,返回 Request Headers。
因为 URLError是HTTPError 的父类,所以我们可以先选择捕获子类的错误,再去捕获父类的错误,这样捕获的代码更加精准,且有利于程序猿处理。

请求到响应信息不足为奇,也不是什么难事,最主要的,是让程序可以持久的”跑起来”,所以,异常处理是爬虫工程师的必修课,需好好掌握。
parse模块
这是一个工具模块,用的地方挺多的,一些常用操作都封装在里面,如下面介绍的几个函数方法。
1.urlparse()
urlparse() 方法可以实现 URL 的识别和分段,返回六个部分的内容,字段分别是 scheme、netloc、path、params、query、fragment。

2.urlencode()
常用的 urlencode() 方法,它在构造 GET 请求参数的时候非常有用——字典转序列化
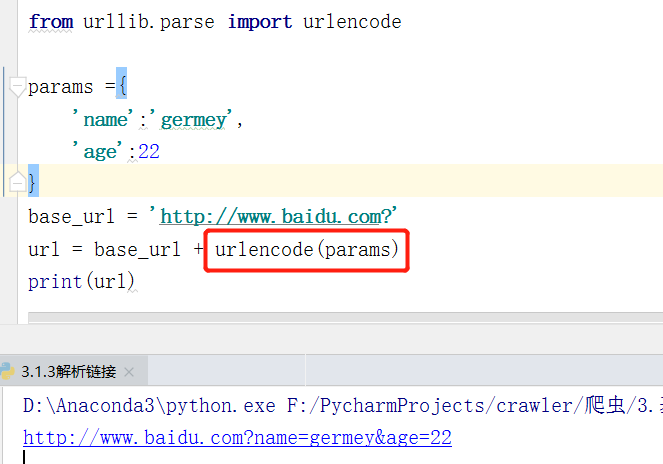
我们知道,使用GET发送请求信息,它的参数是 写在URL中的,那么字典一样的数据(爬取数据大多数为字典)如何传递到URL中呢—— 正是上面讲的序列化了。
3.parse_qs()
有了序列化必然就有反序列化,如果我们有一串 GET 请求参数,我们利用 parse_qs() 方法就可以将它转回字典

4.quote()
quote() 方法可以将内容转化为 URL 编码的格式,有时候 URL 中带有中文参数的时候可能导致乱码的问题,所以我们可以用这个方法将中文字符转化为 URL 编码
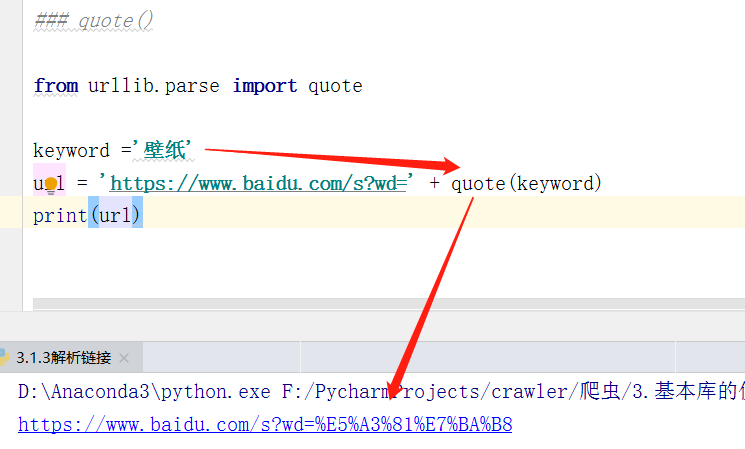
python3 默认编码格式是 Unicode,URL默认不接收这种编码格式,因此我们发送中文字符时,就应该使用相应编码。
5.unquote()
quote() 方法的逆操作,它可以进行 URL 解码(默认是以utf-8编码)
robotparser模块
在介绍rebotparser模块之前呢,我们需要对robots协议进行了解
Robots 协议也被称作爬虫协议、机器人协议,它的全名叫做网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫做 robots.txt 的文本文件,放在网站的根目录下。
robotparse:用来解析rebots文件的类。 robotparser 模块提供了一个类,叫做 RobotFileParser。它可以根据某网站的 robots.txt 文件来判断一个爬取爬虫是否有权限来爬取这个网页。
1 | 接口API: |
使用这个类的时候非常简单,只需要在构造方法里传入 robots.txt的链接即可。这样我们就拿到了一个 robot 对象,再调用can_fetch() 就可以返回是否可用爬取网页的布尔值了。
好了,对urllib库的介绍就到这儿了,下次作者会对第三方请求库requests讲解,这是一个当前的流行库,让我们一起期待吧~
