前言
之前说过反爬机制有很多种,其中JS加密是最为常见的,今天我将介绍有道翻译的JS加密混淆的反爬。当遇到JS加密的时候,就会用到一些综合性比较强的知识点,以及如何去打断点等等,这都是我们应该了解学习的知识。
不然怎么说:一入爬虫深似海…
URL = ‘http://fanyi.youdao.com/’
正常模拟
我们之前学习了 爬虫Day5-requests介绍 和 爬虫Day9-requests实战
知道了如何模拟发出请求,下面我们尝试一下使用 requests 发出请求,看能不能拿到数据。
老规矩,当爬取的网页是动态网页时,先使用抓包分析数据:
抓包分析
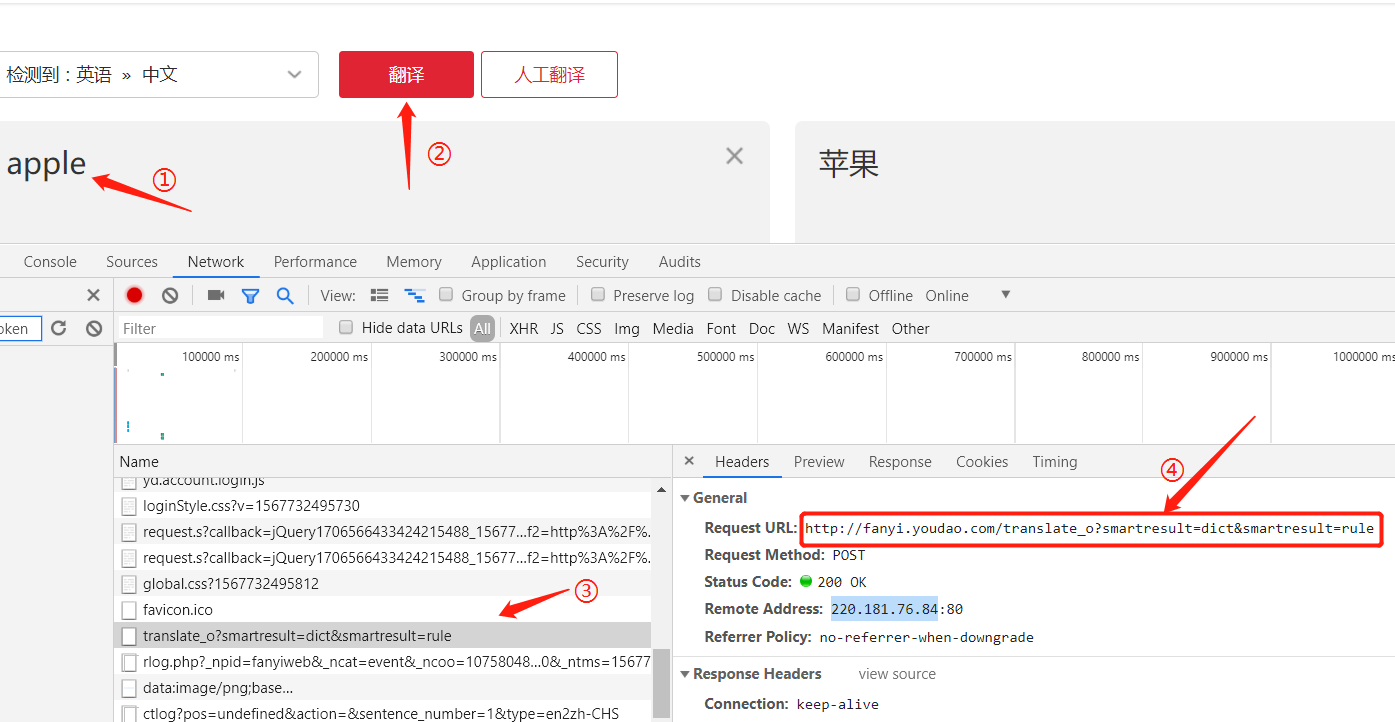
- 输入待翻译的文字
- 点击翻译
- 发现在抓包条目中,发现交互了一条 translate 报文
- 拿到翻译的URL
查看Form表单
我们可以从上面的抓包中看出,这是个POST请求,那么必定有Form Data 表单,客户端与服务器端才能交互数据。
我们往下拉,看看所谓的Form Data 是什么:
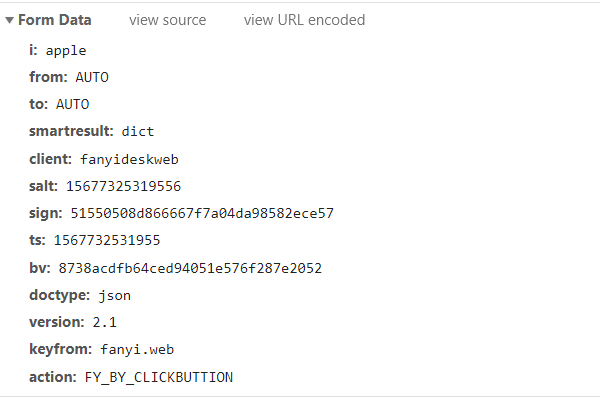
- 发现 i 参数就是我们输入的待翻译文字
- 发现 salt、sign、ts、bv等神秘数字,其实这就是经过JS加密的参数了,我们后面会说。
- 其他的参数皆为常量,正常模拟发送就好了。
模拟请求
接下来使用requests发送模拟请求就不细说了,直接贴图!
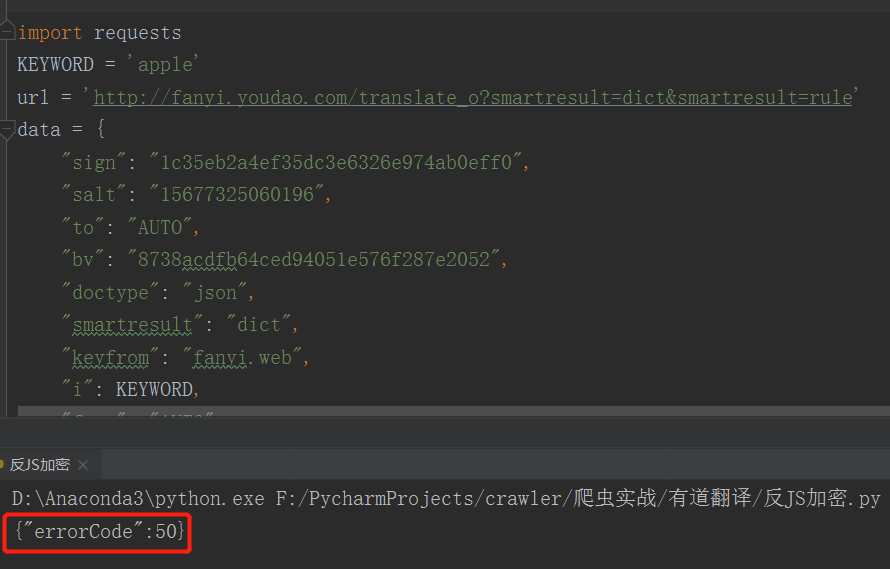
- 我们使用requests 模拟headers、data 发送 post 请求
- 发现返回的结果却是 “errorCode”,证明我们请求失败了,已经被服务器识别出是爬虫脚本
问题出在哪呢? 我们用浏览器能看到的东西,使用requests模拟应该也能拿到一样的数据啊,这就证明了一些类似“有效时间超时”、“蜜獾陷阱”等等一些反爬机制限制了我们制作的爬虫。
那么,如何如何识别这些反爬虫机制呢?
我们先说说常见的反爬机制
- 出现乱码。关键信息不是正常字符,而是通过图片或者乱码来展示(通过渲染让乱码成为可阅读的正常字符)
- 判断是不是请求了网页上用户看不见的数据,而网页源码能看到的节点(蜜獾陷阱)
- 给予假数据(也叫投毒)
- 根据一定行为特征,封IP或者弹验证码。
- 某些请求参数进行JS加密,一般是随机数、时间戳等
那么,按以往我们说的正常套路肯定是搞不到翻译的内容了,我们需要进行反爬,今天将的有道翻译刚好是参数JS加密混淆,我们需要找出它如何加密,然后模拟加密的过程,最终的数据才能够被提交到服务器上。
JS加密反爬分析
还记得我们上面说的那些神秘数字吗?问题就出在这上面。
第一次翻译:
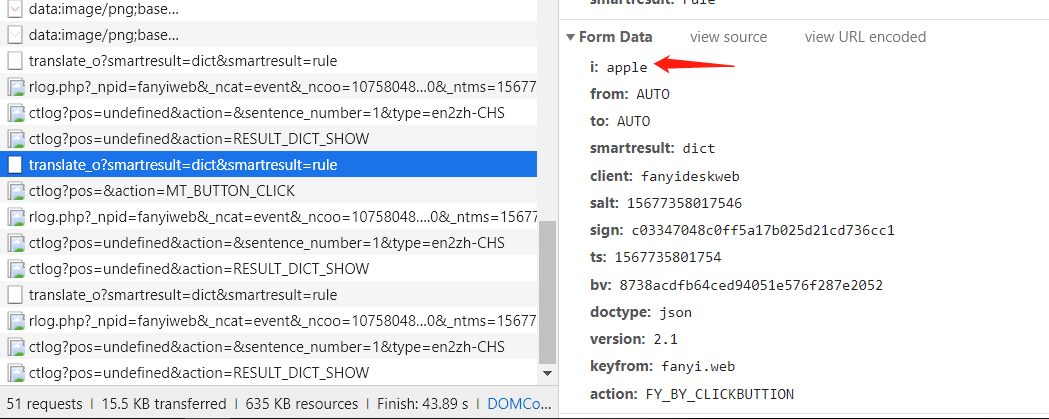
第二次翻译:
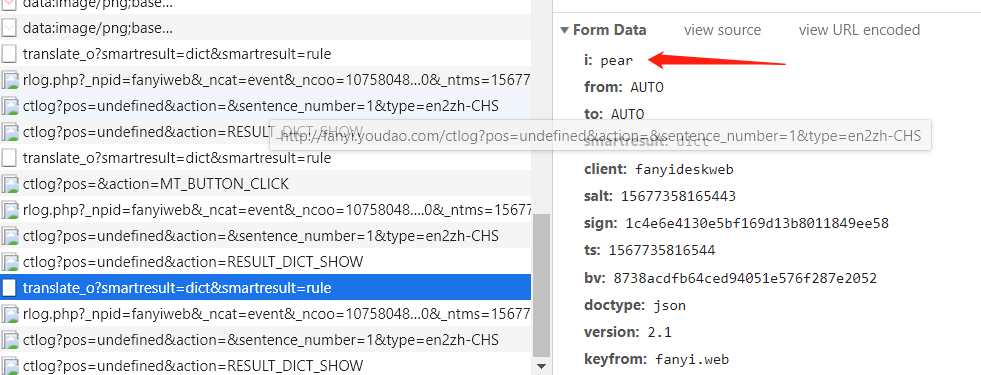
- 可以看到,salt、sign是不断变化的,就这么看是很难看出规律的,这时候,我们就应该去 javascript 里面看看参数对应的数据是怎么来的
javascript脚本分析
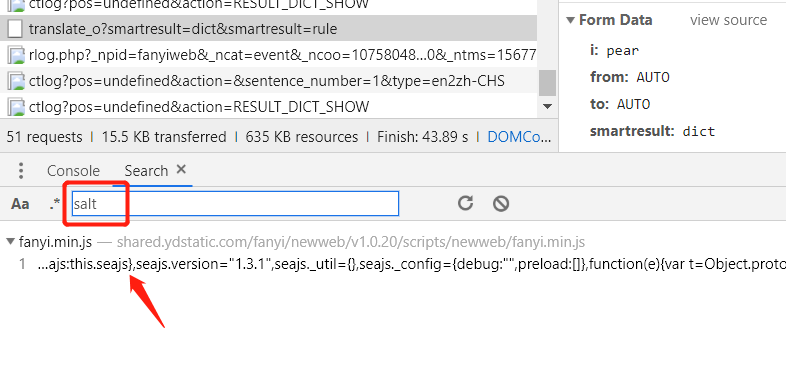
① 按住 ctrl + shift + f 进入search搜索框,输入salt 关键字 。可以看到这是由一个fanyi.min.js文件得到的。
② 进入这个js文件,看看到底是何方神圣
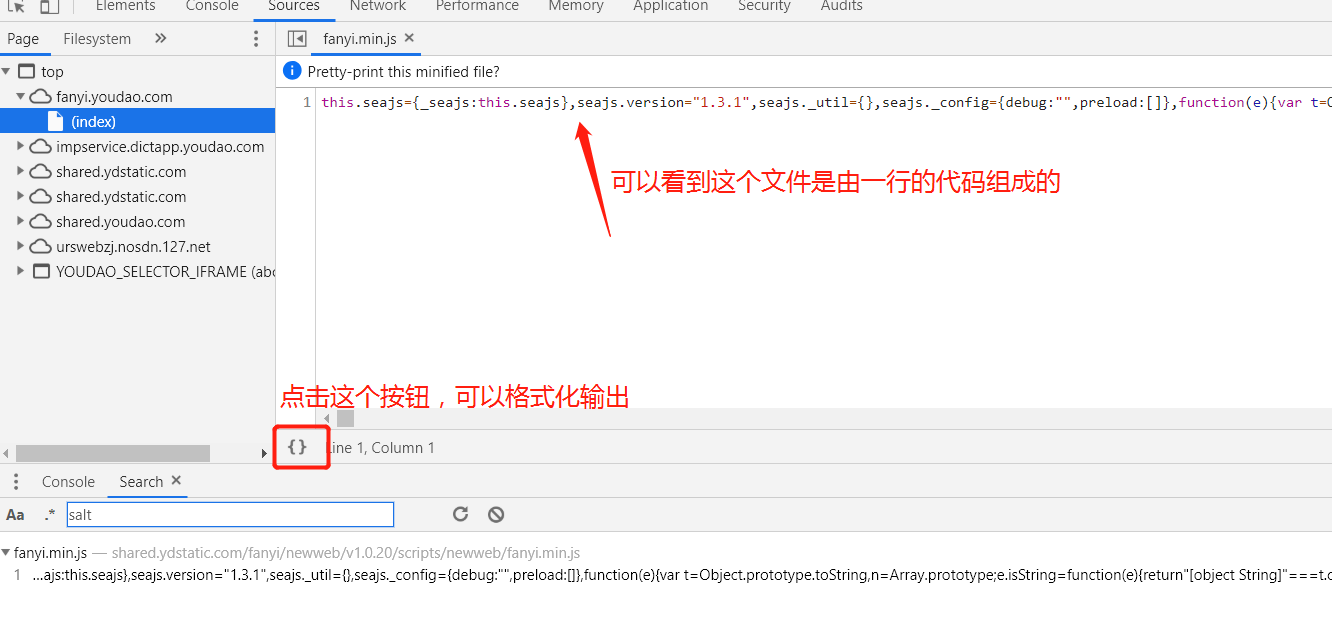
③ 格式化输入后,我们定位salt的位置,
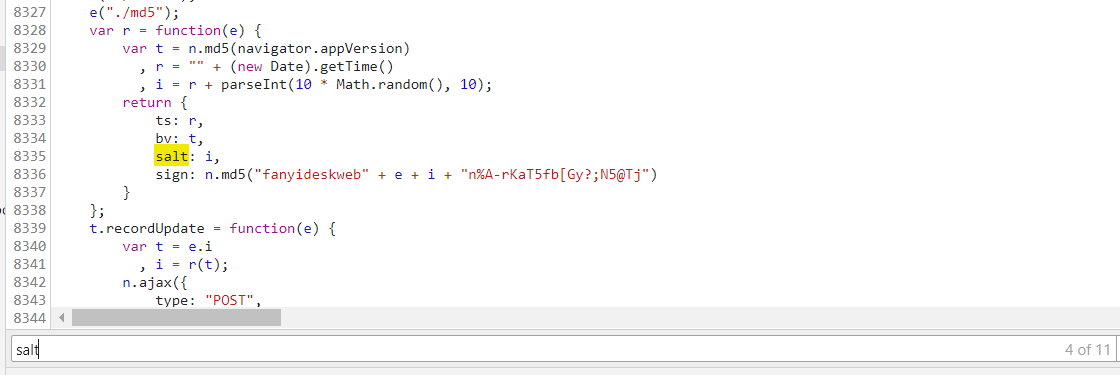
这就是我们加密参数所处的位置了,有了这个,我们就可以观察所谓参数是如何生成的,以及打断点。
js参数断点
我们在相应参数的行头点击一下,这样就打上了断点。打上断点之后我们就可以看到函数运行时相应参数的值分别是多少,根据JS语法推断出各个参数的对应关系
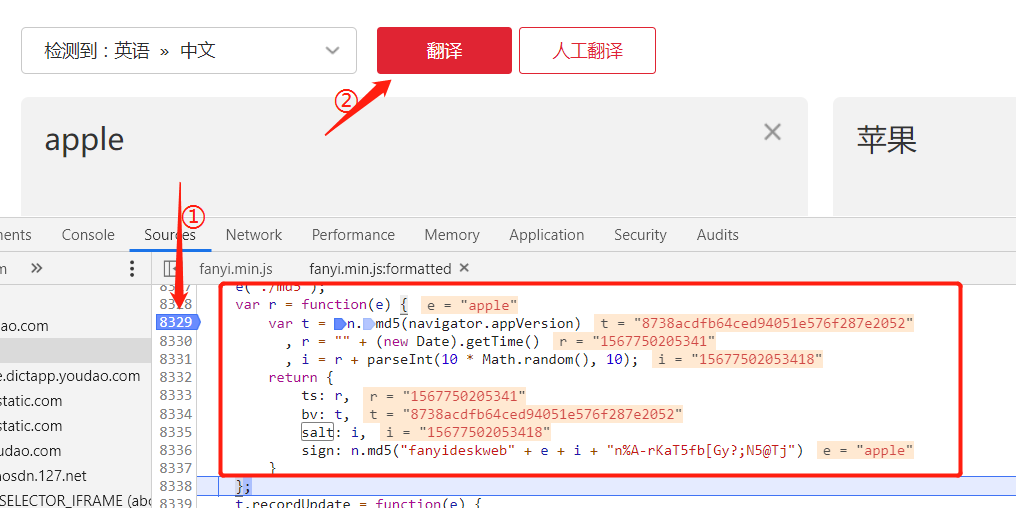
- ‘e’ 是我们待翻译的值;
- ‘bv’ 对应 ‘t’ ,它是一个经过md5加密的参数;
- ‘ts’ 对应 ‘r’,它是一个字符串的时间戳;
- ‘i’ 由 ’r‘ 和一个十以内的随机数组成的;
- ‘sign’ 也是由md5 加密的组合字符串;
对于一些 js 的函数,我们可以到Console 运行一下,看看它返回的值是什么。
① 在‘bv’ 参数中使用md5加密的 navigator.appVersion
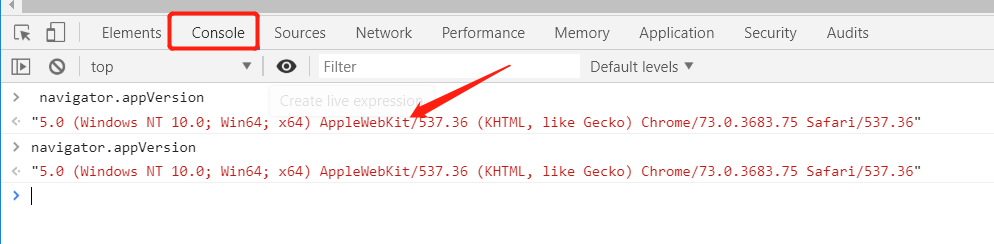
- 可以发现结果是不变的,那么这是一个常量
② r 参数中的 js 函数:(new Date).getTime()
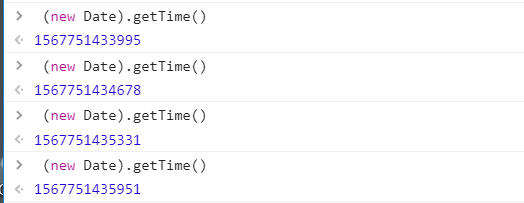
③ i 参数就不用试了,有编程基础的都能看出端倪,这就是一个十以内的随机数
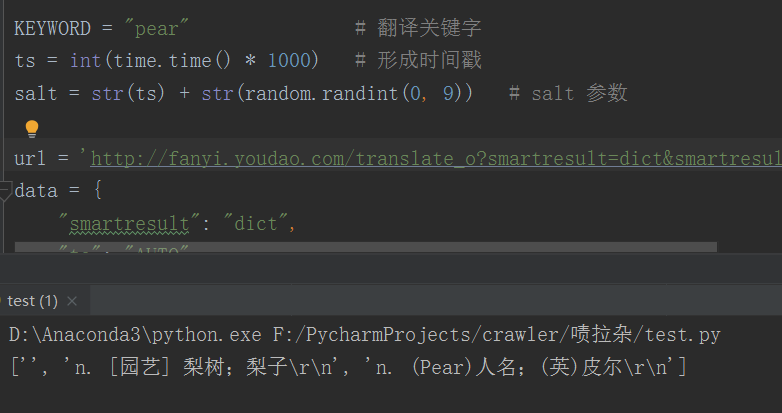
python脚本模拟
知道参数怎么来的之后,我们就可以使用python进行模拟啦~ 发送请求时,携带上这些参数,就ok了!
1 | import hashlib |
运行结果:
写在最后
如何打断点是个很重要的技能,这是一把利器,就看你能不能用好它。
这个JS混淆加密还是比较简单的反爬,还有一些比较难的比如CSS字体加密,就得需要其他方面的知识了,总的来说,爬虫真的是一门综合性很强的课。
一起努力吧~