Requests的基本使用
我们知道在 Urllib 库中有 urlopen() 的方法,实际上它是以 GET 方式请求了一个网页。那么在 Requests 中,相应的方法就是 get() 方法,是不是很方便(使用什么请求方法就用对应的方法名封装的API)
GET 请求
下面是使用requests库发出的简单get请求,是不是相对于urllib,步骤变简单了很多呢?嘿嘿~
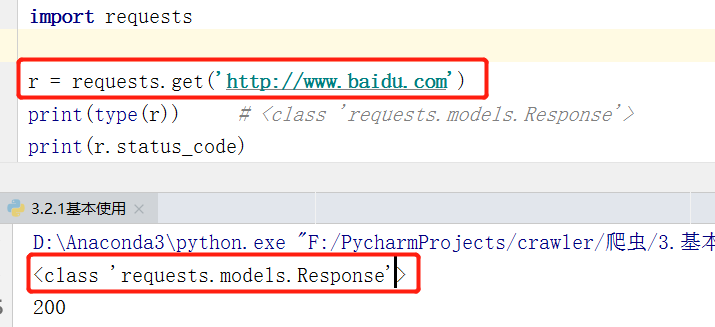
- 响应内容的类型是type,我们可以基于这个对象,使用text方法获取文本,也可以调整编码格式等等。
- 响应状态码封装在status_code这个属性中,200表示正常访问。
模拟其他请求
接下来,在这里分别用post()、put()、delete() 等方法实现了 POST、PUT、DELETE 等请求。requests这些方法时是直接使用的(不像urllib那么隐晦)

附加信息
我们知道,使用百度这样的搜素引擎搜索关键字时,会在url生成类似这样的url,比如我们现在搜索的关键词是python,会生成下面这条url——“http://www.baidu.com/s?wd=python”
那么,在requests中,如何模拟这样的关键词查询呢?
回答:将信息数据存储到字典中,然后利用params这个参数进行传递。

- 我们可以看到,字典的键值被传递到url中。
- 注意字典里值为None 的键都不会被添加到 URL 的查询字符串里。
定制请求头
注意:定制 header 的优先级低于某些特定的信息源,例如:
- 如果在
.netrc中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了 auth= 参数,.netrc的设置就无效了。 - 如果被重定向到别的主机,授权 header 就会被删除。
- 代理授权 header 会被 URL 中提供的代理身份覆盖掉。
- 在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
更进一步讲,Requests 不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的 header 信息都会被传递进去。
二进制流数据
上面例子中,实际上它返回的是一个 HTML 文档,那么如果我们想抓去图片、音频、视频等文件的话应该怎么办呢?我们都知道,图片、音频、视频这些文件都是本质上由二进制码组成的,由于有特定的保存格式和对应的解析方式,所以就需要拿到他们的二进制码。
需要记住的是:用什么保存格式编码就要用对应的解析方式解码
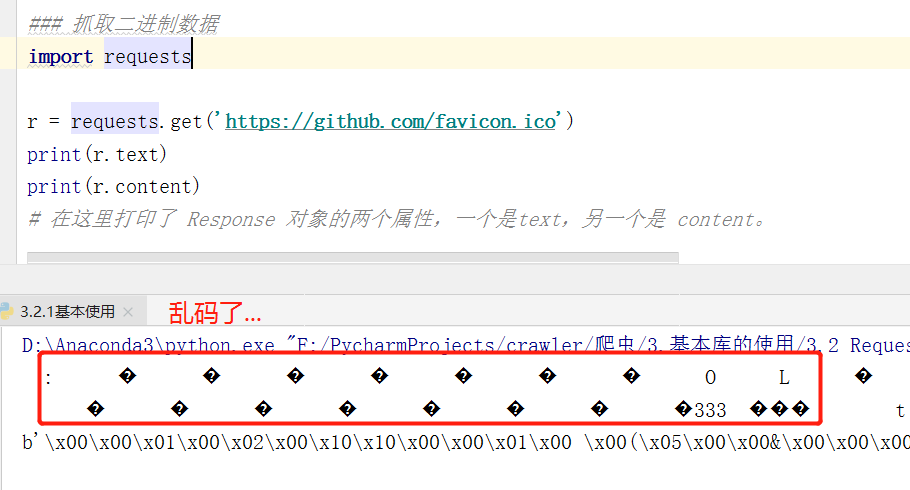
- 前两行便是 r.text 的结果,最后一行是 r.content 的结果。
- 前者出现了乱码,由于图片是二进制数据,所以前者在打印时转化为 str 类型(.text属性会猜测 其编码格式,然后自动给你转码),因此这里就是把图片直接转化为字符串,理所当然会出现乱码
- 而.content会到HTML纯文档中查找Meta标签下的编码,然后进行指定编码。可以发现,打印的结果前面带有一个 b,代表这是 bytes 类型的数据。
得出结论:
r.test返回的是字符串类型,如果返回结果是文本文件,那么用这种方式直接获取其内容即可。
如果返回结果是图片、音频、视频等文件,应该使用 r.content,Requests 会为我们自动解码成 bytes 类型,即获取字节流数据。此时,我们就可以通过写入文件(注意编码格式是wb),将其保存为照片格式。
我建议使用 .content , 然后将二进制数据 编码为 utf-8
关于编码:
编码可谓是蛰伏在黑暗中的精灵,如果你不搞懂他,它就会偶尔出来耍一下脾气…
Requests 会自动解码来自服务器的内容 。 大多数 unicode 字符集都能被无缝地解码 。 请求发出后 , Requests 会基于 HTTP 头部对响应的编码作出有根据的推测 。 当你访问 r.text 时 , Requests 会使用其推测的文本编码 。 不过你也可以找出 Requests 使 用 了 什 么 编 码 , 并 且 能 够 使 用 r.encoding来更改编码方式。如果你改变了编码格式,每当你访问r.text,Request都会使用r.encoding的新值。
不过每一次设置r.encoding都需要去浏览器中查看相应字符集,这很麻烦。我们可以这样写:
1 | r.encoding = r.apprent_encoding # apprent_encoding是在响应报文的头部获取字符集,这样设置比较灵活 |
post 请求
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典(也可以是个元组)给 data 参数。你的数据字典在发出请求时会自动编码为表单形式

是不是觉得好简单?哈哈~ 这就是requests向我们提供的简单接口,然后我们直接拿来调用就行了!
Request的高级用法
文件上传
我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传。使用files关键字传递文件,就可以达到我们想要的效果。
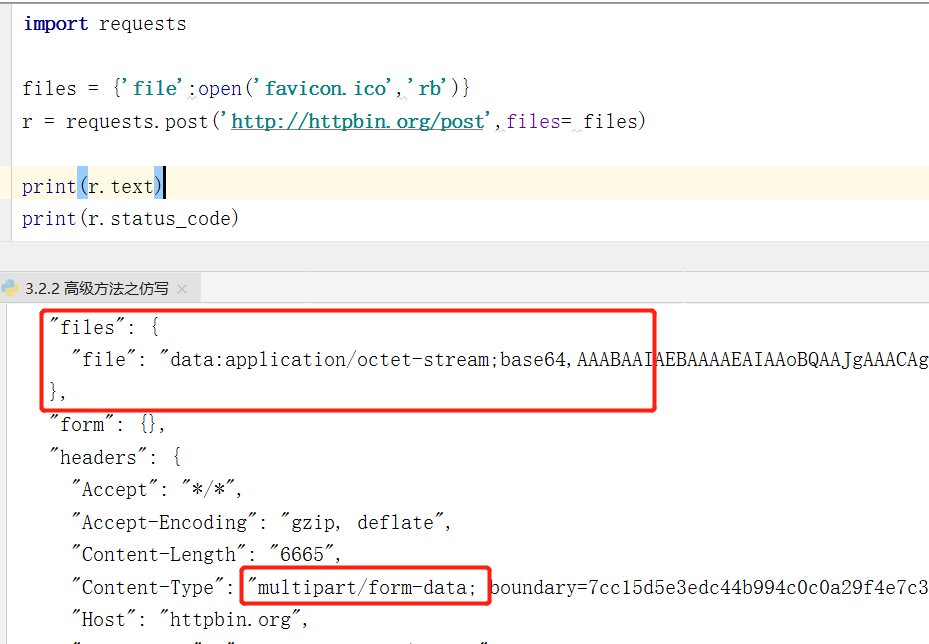
- content-type的值是multipart/from-data,表示是以表单数据提交的,证明请求方法为post
- 发送到网页,需要以字节流形式传输,所以我们打开文件时必须指定为“wb”
- 最后使用files关键字指定传入文件,文件需以字典形式传入(键名是什么不重要)
设置Cookies
在前面我们使用了 Urllib 处理过 Cookies,写法比较复杂,而有了 Requests,获取和设置Cookies 就比较方便快捷了。而且requests有两种设置方法,我们一起来看看吧~
① 在请求报文头中设置
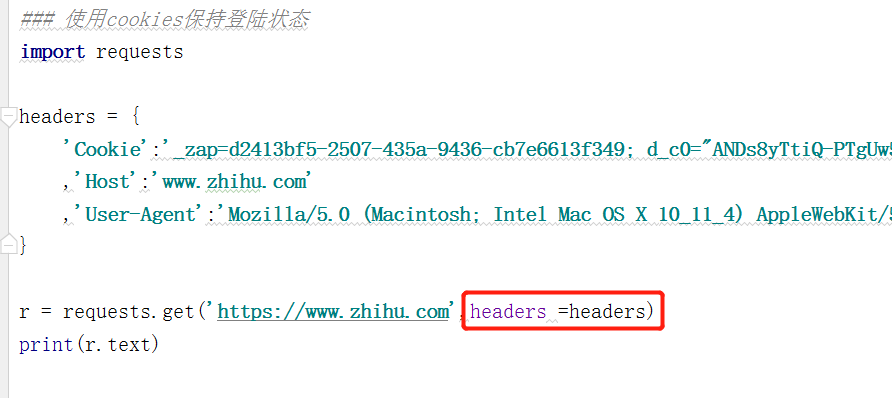
② 通过cookies参数进行传递
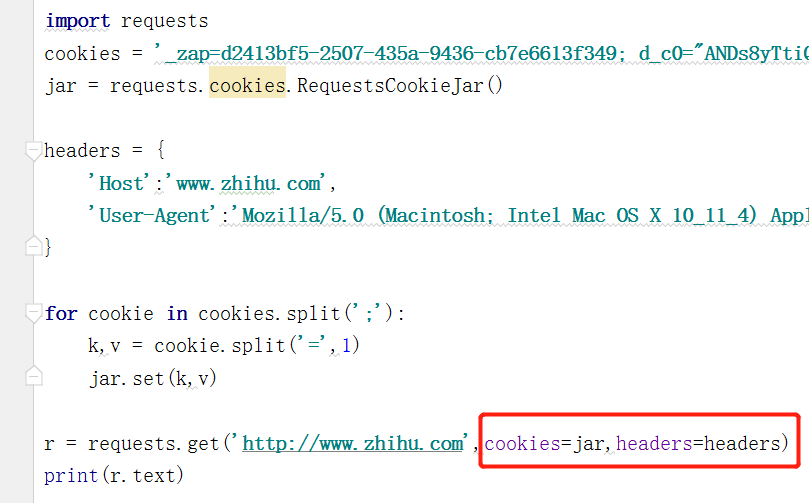
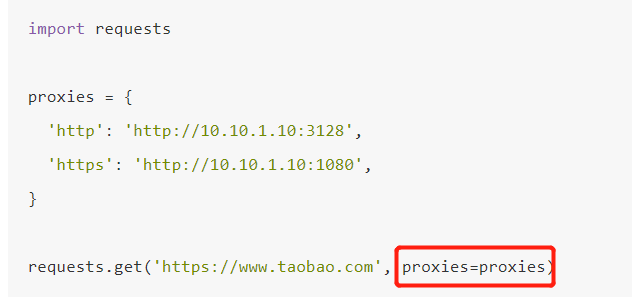
代理设置
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会提出登录验证、验证码,甚至直接把IP给封禁掉。(我就曾使用selenium对淘宝网进行爬取,结果没爬几页,发现被淘宝反爬虫给识别出来了,这就很尴尬了…)
那么为了防止这种情况的发生,我们就需要设置代理来解决这个问题,在 Requests 中需要用到 proxies 这个参数。
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能会收到一个响应,甚至到最后收不到响应而报错。为了防止服务器不能及时响应,我们应该设置一个超时时间,即超过了这个时间还没有得到响应,那就报错,或者谁用异常处理来处理这类事情。
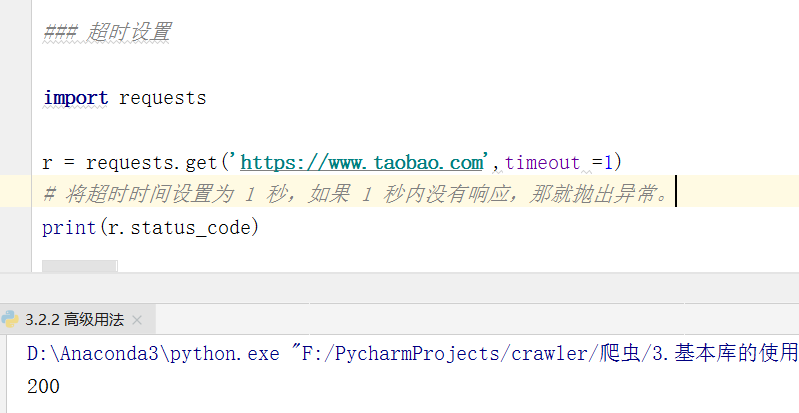
- 设置超时时间需要用到 timeout 参数(默认是None)。这个时间的计算是发出 Request 到服务器返回Response 的时间。
上面就是requests的简单介绍了,是不是发现功能都被封装称为各个API中,我们只需要进行调用就好了,有没有像我当初一样,被requests这个库的魅力所感染到了呢?
