前言
之前介绍requests 这个库的时候在文尾说过要做一篇实战的文章,今天突然想起,然后就写一下咯。
爬虫Day5-requests介绍今天的主题是——使用 requests请求库 和 re 解析库进行爬取当当网热门top 500书籍。
url = http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-1
网页省察
第一步:我们进入url 链接之后,按F12进入开发者模式
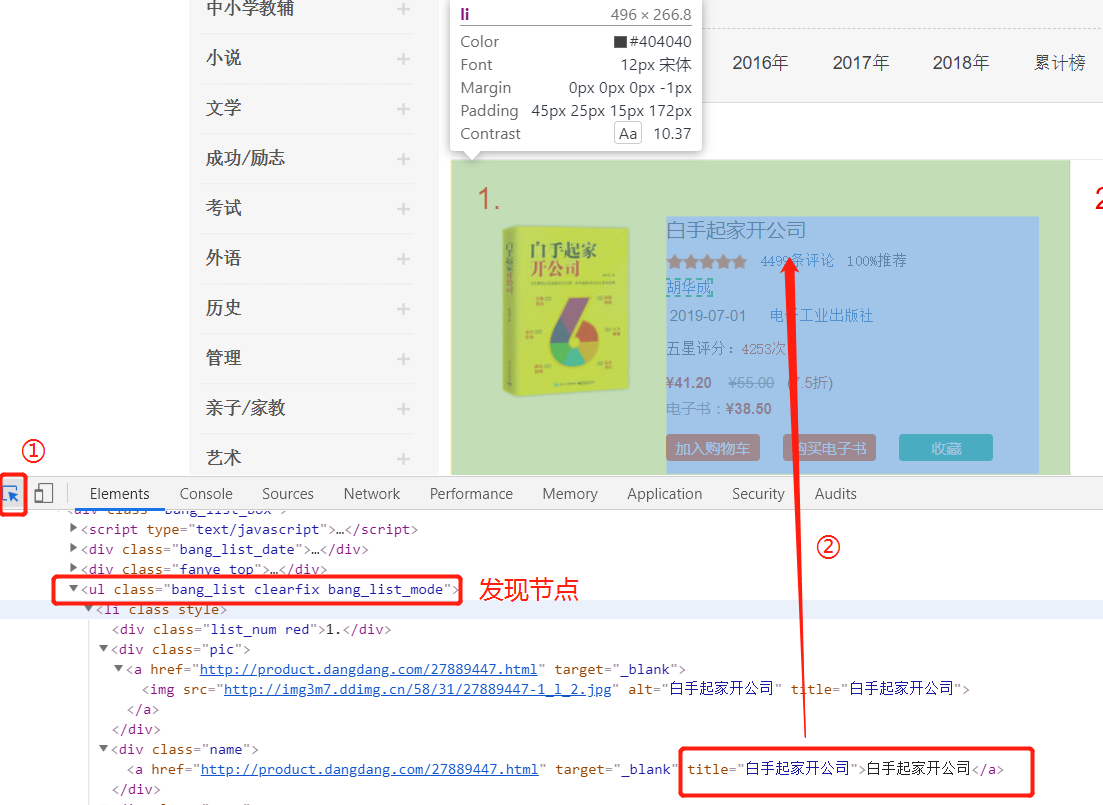
- 总结出以下规律:所有书籍都存放在一个 ul 标签下面
- 每一本书都是 一个li 节点
第二步:切换页码数,观察 url 变化
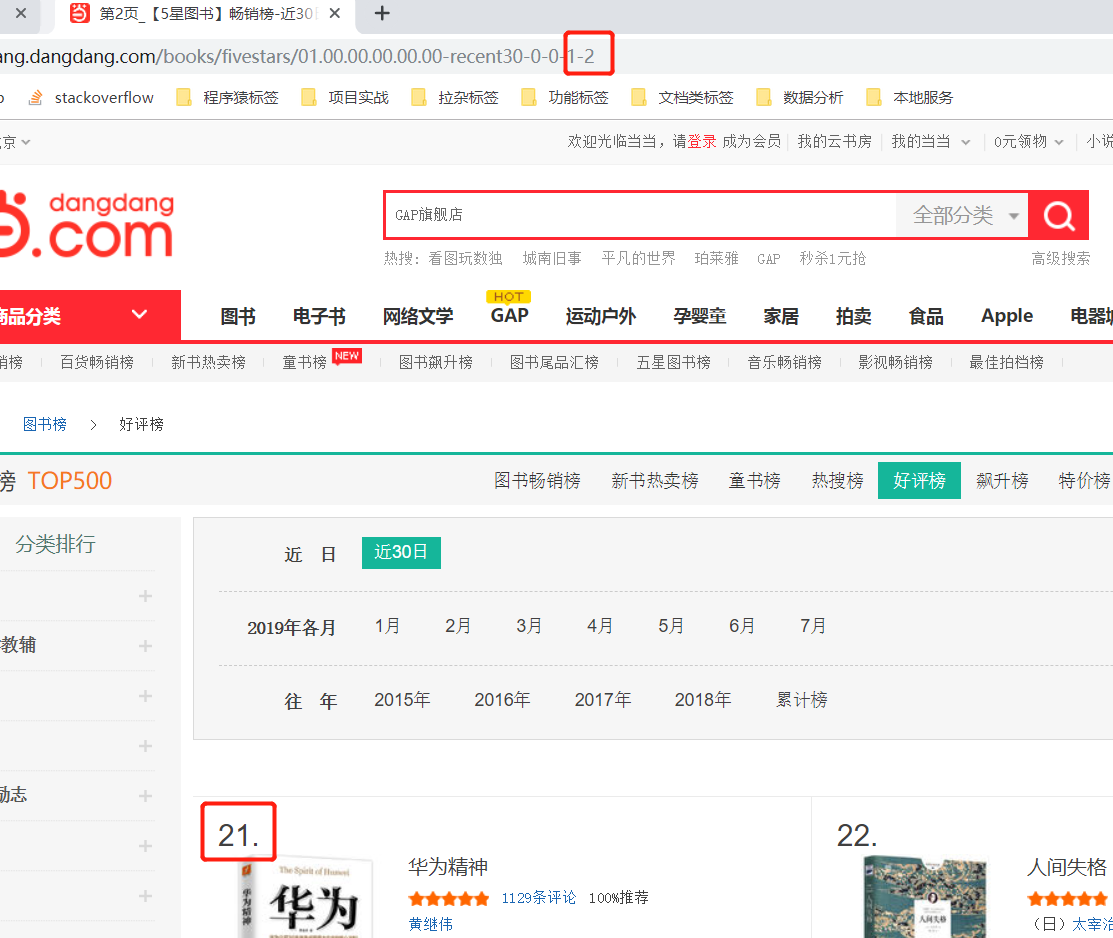
- 发现 url 链接最后面的数字发生改变—— 由”1“ 变成 ”2“,这正好对应上我们翻页的页码数
- 每一页的书籍量为20 , Top 500 的书籍 爬取 25 个连接就可以爬取完毕
动手写代码
1 | def get_page(page): |
解析
我们点开的每一个 li 节点,观察我们需要爬取的节点信息
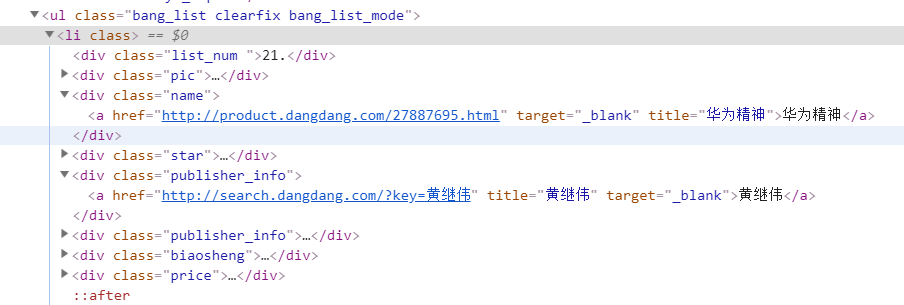
- 发现每一段信息都有一个div 存储着,我们只需要re 正则匹配出来,就欧克了
解析代码如下:
1 | def parser_page(html): |
我们先看看 这个 叫 “doc” 生成器 的内容,使用 for 循环遍历出来:
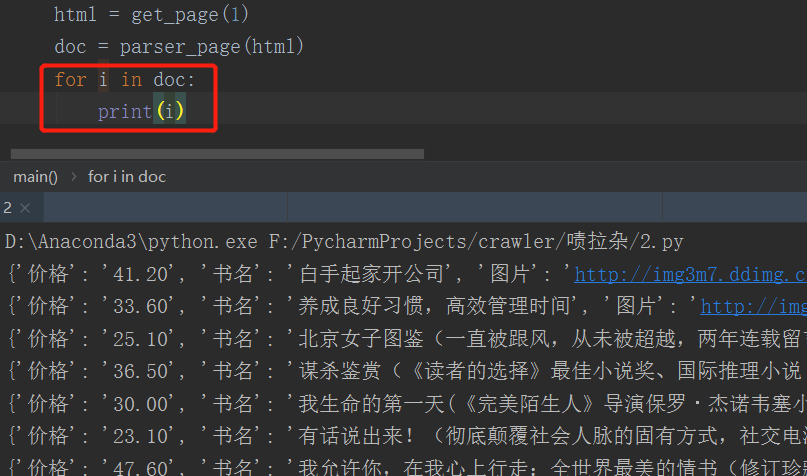
perfect! 这样我们就把信息完美的抓取下来了。
写入文件
接下来,我们就将内容写入文件,以便后期的数据分析。
1 | with open("book.txt","w",encoding="utf-8") as f: |
我们运行一下代码,效果如下:
爬虫完善
最后,我们需要控制爬取速率,做一个有素质的爬虫,毕竟一直爬取别人网站,服务器也会受不了的呀。并且,加上异常处理,一个简单的小爬虫就写好了。
完整代码如下:
1 | import requests |
后记
可以发现,使用 re 来解析库的难度还是有的,不过,我想说的是,使用什么模块并不重要,只有最适合当前需求的模块,取决于你如何去灵活运用它,编程语言也是这样。