之前的urllib实战中我们谈到了BeautifulSoup这个解析库,那么…是不是应该来一篇详细介绍呢?
今天,他来了!!

BeautifulSoup的基本使用:
拿到网页数据:
一般来说,我们使用解析库的前提,已经是通过请求库拿到了网页的数据,假设现在由下图的 html 变量存储的数据正是我们请求的文本内容,下面我们将使用BeautifulSoup进行加工解析。

获取Soup对象:
使用BeautifulSoup方法,第一个参数传入 HTML字符串文本,第二个参数传入的是解析器的类型,在这里我们使用
lxml。不指定会使用默认的解析器,但是会发出警告
1 | from bs4 import Beautifulsoup |
运行后,发现内容如下(发现不完整的HTML字符串被补齐了):

属性选择
调用 soup 的各个方法和属性(选择器)对这串HTML代码解析。这个soup对象支持 “.” 获取节点操作,也可以通过”.”表达嵌套关系。
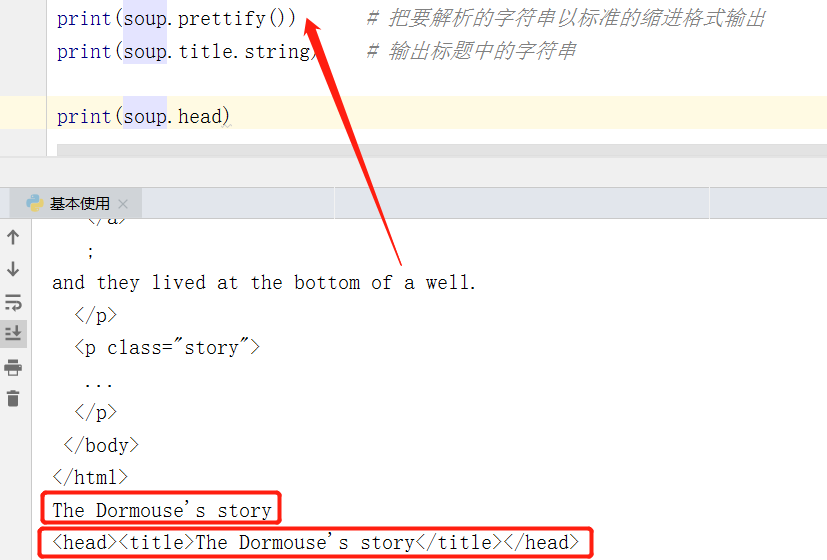
- 我们直接拿到的soup打印不美观,使用prettify()方法可以打印出树形结构的 html 文本
- 这里我们打印 title 的文本内容,以及 head 节点信息
上面就是BeautifulSoup的使用流程,有时候,我们需要的内容存放于某些节点中,这些节点有它的特征,我们可以通过选择器获取这些节点,最后拿到我们需要的结果。
1 | 对于某些节点,我们使用嵌套选择来选中它非常麻烦,那么,就有了节点选择器,根据其CSS编写的 类、id 这样的属性进行选择。Beautifulsoup 很快就能找出匹配的标签。 |
节点选择器:
选择节点:
直接通过调用节点的名称就可以选择节点元素了,这种选择方式速度非常快,如果单个节点结构话层次非常清晰,可以选用这种方式来解析。
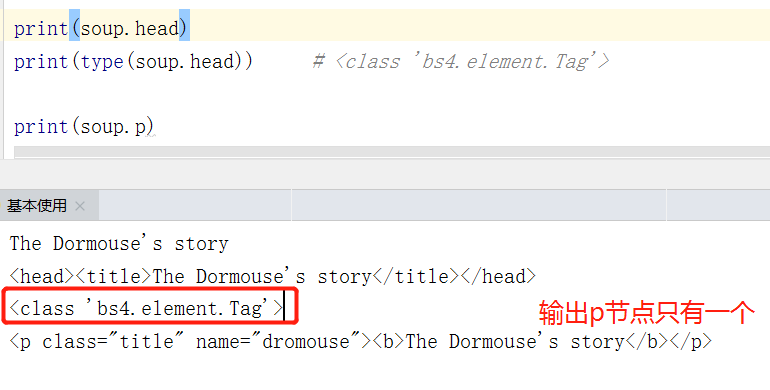
注意,我们的选择器是基于soup这个对象的
输出了soup.head的类型,是 bs4.element.Tag 类型.这是 BeautifulSoup 中的一个重要的数据结构,经过选择器选择之后,选择结果都是这种 Tag 类型,它具有着一些属性,比如 string 属性(输出文本信息),可以进行获取属性、嵌套等操作。
不过这种选择方式只会选择到第一个匹配的节点,其他的后面的节点都会忽略——比如我们打印的p节点,只呈现一个信息(html字符串中有三个p节点信息)
获取属性值:
每个节点可能有多个属性值,比如id,class 等等,我们选择到这个节点元素之后,可以调用 attrs 获取所有属性。
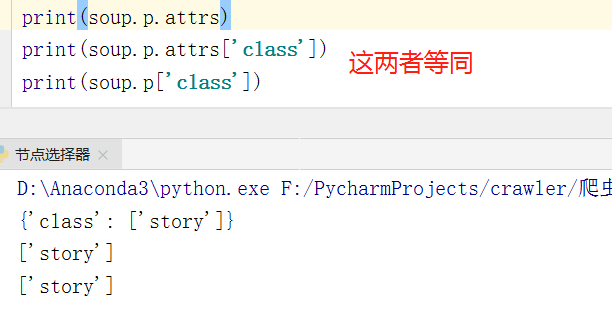
- 可以看到 attrs 的返回结果是字典形式,把选择的节点的所有属性和属性值组合成一个字典。因此,可以通过键值形式进行取值传入节点的属性,获取该节点的属性值
contents 属性:
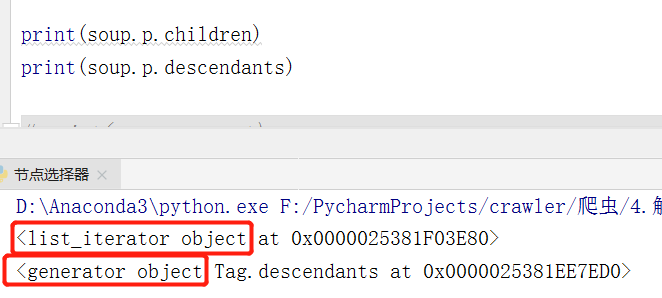
选取到了一个节点元素之后,如果想要获取它的直接子节点的信息 (不包含子孙节点),可以调用
contents 属性(和直接选择不同的是,contents返回的列表包含了所有子节点和所有文本信息)
关联选择:
我们在做选择的时候有时候不能做到一步就可以选择到想要的节点元素,有时候在选择的时候需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等等。这里列出了获取节点的各个方法:
| Children | 查询某个节点的直接子节点(返回一个迭代器) |
|---|---|
| Descendants | 查询某个节点的所有子孙节点(返回生成器) |
| parent | 查询某个节点的元素的父节点 |
| Parents | 查询某个节点的元素的祖父节点(返回生成器) |
| soup.a.next_sibling | 查询某个节点的下一个节点 |
| previous_sibling | 查询某个节点的上一个节点 |
| next_siblings 和 previous_siblings | 分别返回所有前面和后面的兄弟节点的生成器。 |
需要注意的是:上面这些节点选择,但凡涉及到多个节点内容,就会返回一个生成器类型。
关于这些节点选择,我们要注意 html 树型结构的排列关系,例如,我们不能跨越父级节点,去拿到另一个子孙节点的内容。
调用 API
前面我们所讲的选择方法都是通过属性来选择元素的,这种选择方法非常快,但是如果要进行比较复杂的选择的话则会比较繁琐,不够灵活。所以 BeautifulSoup 还为我们提供了一些查询的方法,这里介绍非常常用的 find_all()、find() 等方法,我们可以调用方法然后传入相应等参数就可以灵活地进行查询。
find_all( )
查询所有符合条件的元素,可以给它传入一些属性或文本来得到符合条件的元素,并使用一个列表进行返回。
1 | # 它的API 如下: |
我们接下来针对它的 API 下的属性进行介绍
①name:根据标签名选择节点
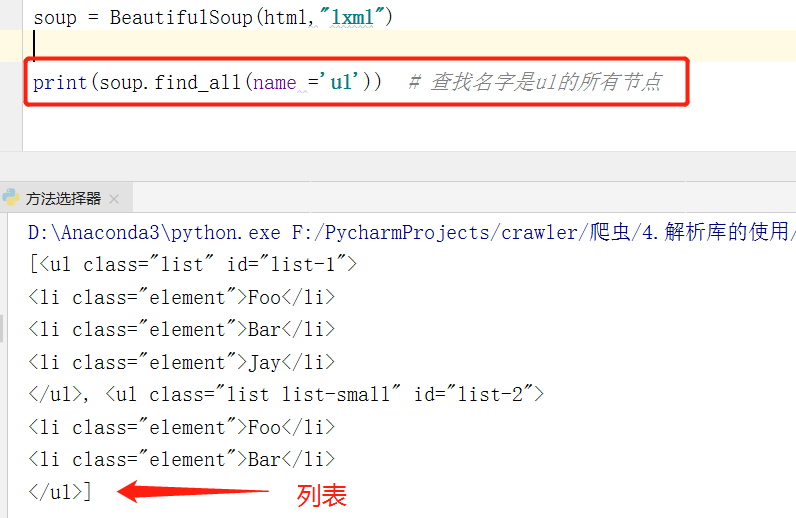
- 方法选择器会返回一个Tag标签的类型,也就是说,其支持嵌套获取元素、层层迭代使用find_all等等操作。
- 当name=True时,匹配所有标签。
string 属性获取文本:
如果我们想拿到节点中的文本,该怎么做呢? 使用列表切片方式取值,再调用.string属性,即可获取文本。
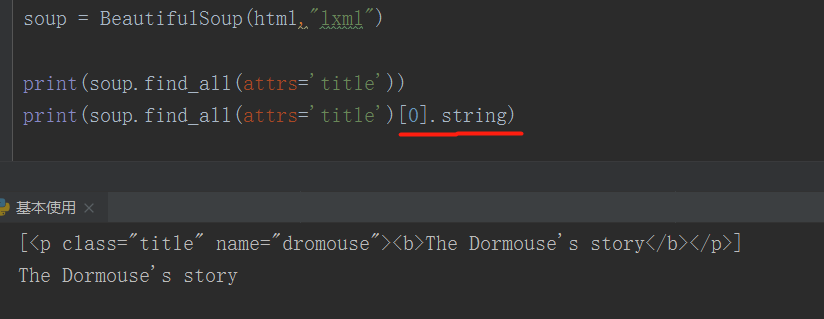
② attrs / id :根据属性值匹配
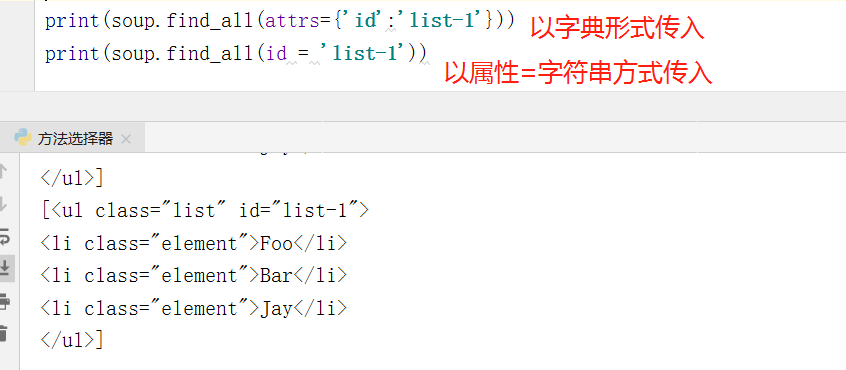
可以通过这些attrs、id 这两个关键字对我们需要的节点传入进行匹配
③ text:用来匹配节点的文本,文本参数 text是用标签的文本内容去匹配,而不是用标签的属性。
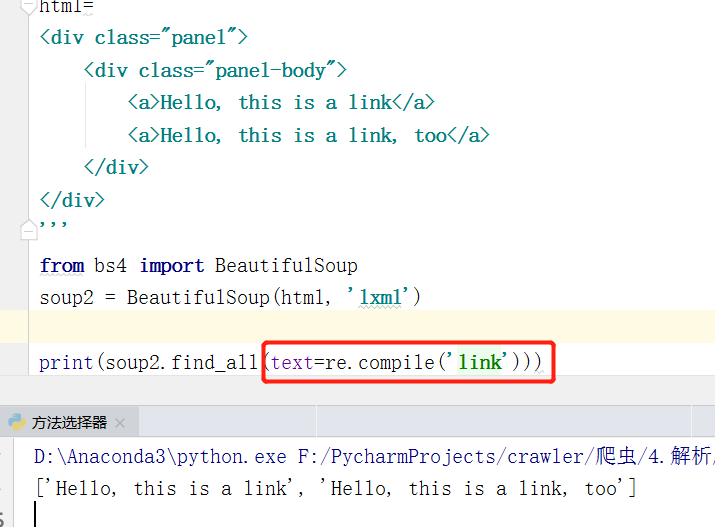
- 传入的形式可以是文本字符串,也可以是正则表达式对象(compile方法生成的对象)
- 举例:text = “Hello,this is a link” 这样的形式进行匹配节点。
find( )
find() 方法返回的是单个元素,也就是第一个匹配的元素。类型依然是 Tag 类型。(当某个标签只有一个是使用find比较好,因为find返回一个Tag类型,利于我们后续操作。 而find_all返回一个列表,这是最大的区别了,有时候我们需要拿到Tag类型的节点,这样对我们的后续操作更为便利),跟find_all很相似,API都是相同.
CSS选择器
BeautifulSoup 还提供了另外一种选择器,那就是 CSS 选择器。如果学过前端,那么这个选择器简直是为你量身定做的。
我们只需要调用 select() 方法,传入相应的 CSS 选择器即可(个人比较喜欢这个选择器)
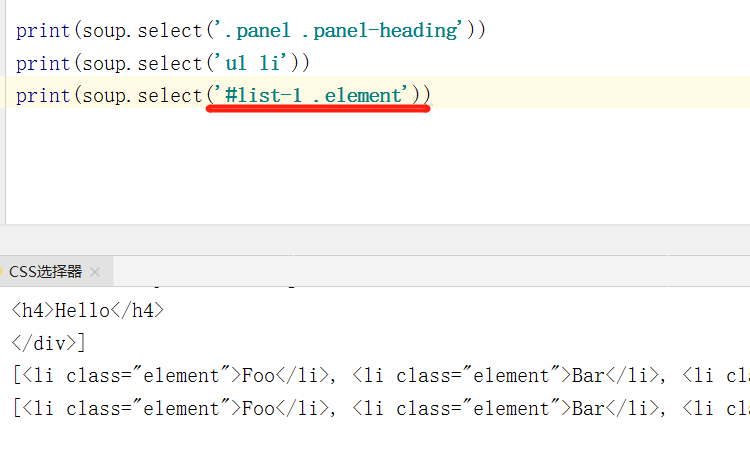
- CSS选择器是 BeautifulSoup 最大的特性,比较简便,且好理解
- 例如: id =“xx” 我们就可以写成 ‘#xx’,传给select 方法匹配。
获取文本
经过节点选择,我们已经匹配到我们需要的节点了,接下来应该是获取文本内容了,通过Tag 类型的string 属性,我们可以拿到文本内容,还有一个方法那就是 get_text(),同样可以获取文本值。
只需基于 Tag类型,调用 get_text() 方法即可。不过需要注意的是: .get_text()会把你正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。假如你正在处理一个包含许多超链接、段落和标签的大段源代码,那么 .get_text() 会把这些超链接、段落和标签都清除掉,只剩下一串不带标签的文字。
所以,get_text()方法一般留到节点匹配之后使用,不然会影响我们获取节点
获取属性
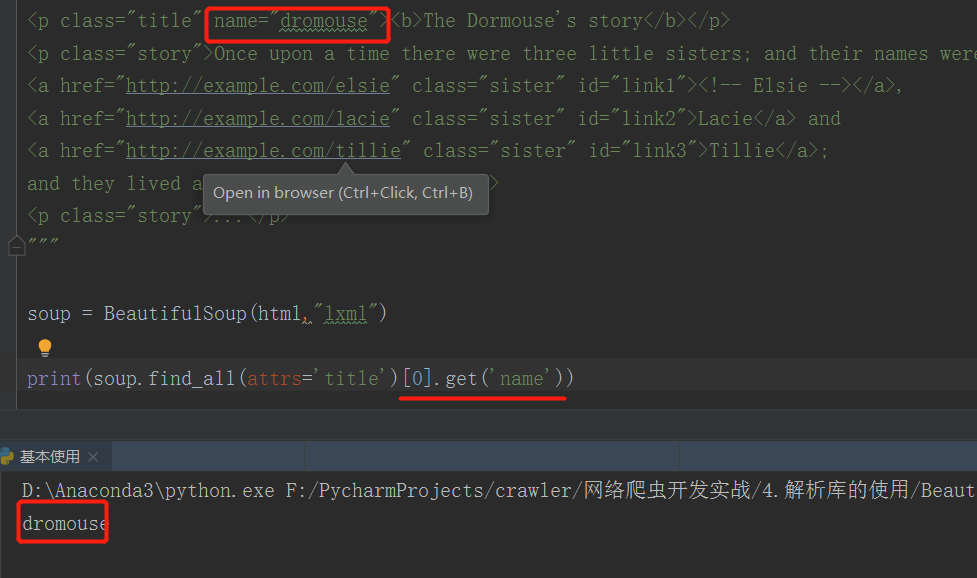
- get 属性还是比较常用的,例如获取 a 标签的href 属性,我们就能得到链接了: get(”href“)
写在最后:
- 说一下节点选择的建议:页面布局总是不断变化的。一个标签这次是在表格中第一行的位置,没准儿哪天就在第二行或第三行了。如果想让你的爬虫更稳定,最好还是让标签的选择更加具体。如果有属性,就利用标签的属性。
- 解析库呢,就像一把锤子,使用的是我们,我们学会如何使用一把锤子的同时呢,也要关注什么时候去使用它,不要手上握着一把锤子,看任何问题都是钉子。使用适当的解析库去拿到我们需要的内容才是我们应该做的,使用什么样的锤子并不重要。
不经意间,爬虫专栏已经走到的Day6了,过阵子应该会更新 爬取网站的实战。还是那句话,学理论归理论,但只有实战才能使我们将其内化,成为我们真正的技能。