HTTP基础
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
不了解TCP/IP的童鞋,请穿越到这里:计算机网络Day1-TCP/IP协议
主要特点:
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5、支持B/S及C/S模式。(俗称浏览器/服务器及客户端/服务端)
HTTP之URL
URL:用来传输数据和建立连接,URL全称为”统一资源定位符”。我们在网页上所干的事情,本质上就是找到特定的资源进行访问,然后获取我们需要的东西
通俗的讲,它是一个链接,它能使我们从互联网上找到我们访问的资源。
一个丰富详细的URL可以包含以下部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在”HTTP”后面的“//”为分隔符
- 域名部分:该URL的域名部分为 “www.4399.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/flash/58508.html”
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
- 锚部分:从“#”开始到最后,都是锚部分。
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
网页交互过程:
我们在浏览器中输入一个 URL,回车之后便会在浏览器中观察到页面内容。实际上这就是和服务器做交互行为, 通过发送请求,再到服务器响应服务,这就完成了我们获取资源的目的。
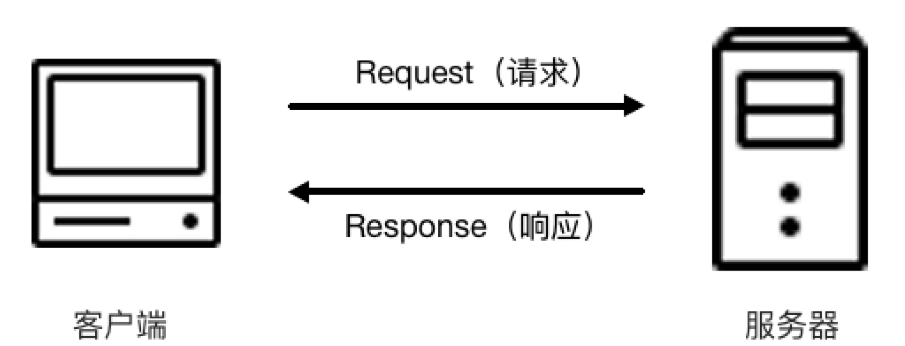
客户端请求–Request:
Request,即请求,由客户端向服务端发出。可以将Request分为四部分:
- 请求方法(Request Method)
- 请求链接(Request URL)
- 请求头(Request Headers)
- 请求体(Request Body)
如图:
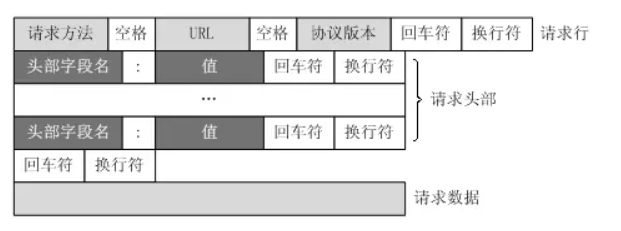
Request Method
请求方式,请求方式常见的有两种类型,GET 和 POST。
Get:
我们在浏览器中直接输入一个URL 并回车,这便发起了一个 GET 请求,请求的参数会直接包含到 URL 里(GET 方式请求提交的数据最多只有 1024 字节)
Post:
Post 请求大多为表单提交发起,如一个登录表单,输入用户名密码,点击登录按钮,这通常会发起一个 POST 请求,其数据通常以 Form Data 即表单的形式传输,不会体现在 URL 中。(POST 方式请求提交的数据没有限制)
而且Post请求在Request Headers中的Content-Type标识——只有设置为application/x-www-form-urlencoded 才是Post请求。
其他请求方式
我们平常遇到的绝大部分请求都是
GET 或 POST 请求,另外还有一些请求方式,如 HEAD、PUT、DELETE、OPTIONS、CONNECT、TRACE,我们简单将其总结如下:

Request Headers:
请求头,用来说明客户端要使用的附加信息,比较重要的字段有:Cookie,Referer、User-Agent 以及 Content-Type等等。
Request Headers 是 Request 等重要组成部分,在写爬虫的时候大部分情况都需要设定 Request Headers。
因为python爬虫脚本,默认的请求头参数会表明 这是由 python 发出的请求,而不是浏览器。(服务器一看,这不是明着来搞我吗,一条ACL写下去,请求头是脚本发起的请求就访问不了我了)
Request Body:
请求体,一般承载的内容是Post请求的Form Data,即表单数据,其一般承载着发送往服务器的信息。同时,服务端需要支持post请求方法,才能够接收我们发送的数据,同时,它会对着请求数据进行回复。
例如注册,我们把账号密码在表单中填充完整,然后点击注册,这时候就已经发送数据往服务器了,服务器验证规则成功后,会在数据库记录,然后我们就可以登录了。
而对于Get请求中,Request Body的内容为空。 所有信息存储在 URL中。
服务器响应–Response
Response,即响应,由服务端返回给客户端。
Response 可以划分为三部分:
- Response Status Code
- Response Headers
- Response Body
Response Status Code:
响应状态码,此状态码表示了服务器的响应状态,如 200则代表服务器正常响应,404 则代表页面未找到,500则代表服务器内部发生错误。
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
Response Headers:
响应头,其中包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等,下面对一些常用的头信息说明:
Date:日期,标识 Response 产生的时间。
Last-Modified,指定资源的最后修改时间。
Content-Encoding,指定 Response 内容的编码。
Server,包含了服务器的信息,名称,版本号等。
Content-Type,文档类型,指定了返回的数据类型是什么,如text/html 则代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回了图片。
Set-Cookie,设置Cookie,Response Headers 中的 Set-Cookie即告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
Response Body:
响应体,响应的正文数据都存放于此,如果请求一个网页,它的响应体就是网页的HTML代码,或者是Json格式的数据;请求一张图片,它的响应体就是图片的二进制数据。
爬虫的解析都是根据响应体进行操作的。
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 在浏览器键入URL后,向DNS服务器发出地址解析,拿到对应IP
- 检查是否携带端口号,如果有则携带端口号参数进行访问;如果没有,则添加上默认端口号进行访问,发起TCP请求连接。
- 建立连接后,浏览器根据文件(URL中表明的资源)发出HTTP请求,该请求报文作为TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求进行响应,返回HTML格式的代码
- 浏览器断开TCP连接,根据HTML代码进行渲染并返回。
好了,以上就是简单的讲解了HTTP基础内容,下期我会讲解爬虫的原理基础,以及实现过程。Bye~