前言
除了我们上节讨论过元组、列表外,python基本数据类型中,还有字典这种性能非常出众的序列。
我们这一篇将讨论字典的本质,如何实现的、以及字典性能如此出众的原因。
字典的键
在python的标准库里的所有映射类型都是利用 dict 来实现的,因此它们有个共同的限制——即只有可散列的数据类型才能用作这些映射里的键(只有键有这个要求,值并不需要是可散列的数据类型)。
什么是可散列的数据类型:
可散列的数据类型是指原子不可变的数据类型,如:str、bytes 和整数类型 都是可散列类型,包括frozenset 也是可散列的,因为根据其定义,frozenset 里只能容纳可散列类型。也就是说,字典的键只能是数据不可变的值。
所以,列表不能作为字典的键。那么不可变的元组能否作为键呢?
答案是:只有当元组的内部元素都是可散列类型的值的情况下,元组才是可散列的。
字典是 Python 语言的基石。模块的命名空间、实例的属性和函数的关键字参数中都可以看到字典的身影。
跟它有关的内置函数都在__builtins__.__dict__模块中。正是因为字典至关重要,Python 对它的实现做了高度优化,而散列表则是字典类型性能出众的根本原因。
散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。
在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
Python 会设法保证大概还有三分之一的表元是空的,当快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。(始终维持三分之一这个阀值)
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中使用hash() 方法来做这件事情。
散列表算法
为了获取 my_dict[search_key] 背后的值
①Python 首先会调用hash(search_key) 来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。
②若找到的表元是空的,则抛出 KeyError 异常;若不是空的,则意味着表元里会有一对 found_key:found_value。
③这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value(也就是字典的值)。
散列冲突:
如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为搜寻表元时,是使用偏移量进行查找的,所以有一定小概率上出现散列冲突。
解决方法是这样的:散列表算法会使用退避算法(另取偏移量)重新当作索引进行寻找表元,直到找到value,或者发生KeyError。
表元扩充:
我们可能遇到过这种情况,在循环字典时,试图对字典进行修改,比如:
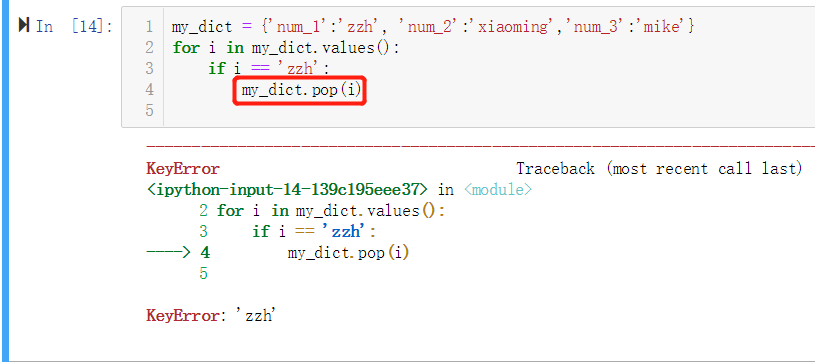
然后望着报错怀疑人生…
解决方法有以下两种:
- 将字典临时转为列表;
- 遍历字典时将要修改、删除的值放到另一个字典中,遍历结束后再对原字典进行更新
但我们要研究的永远不是怎么做,而是为什么要这么做~
字典遍历过程中进行修改发生报错的原因:
往字典里添加新键或修改字典内容时,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。
如果你在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环很有可能会跳过一些键——甚至是跳过那些字典中已经有的键。(所以python并不允许一边遍历一边修改字典)
字典查询的本质
字典的查询速度是很快的,有人就做过这么一个实验,填充十倍递增的数据,看看不同容器(字典、集合、列表)的查询速度是多久。
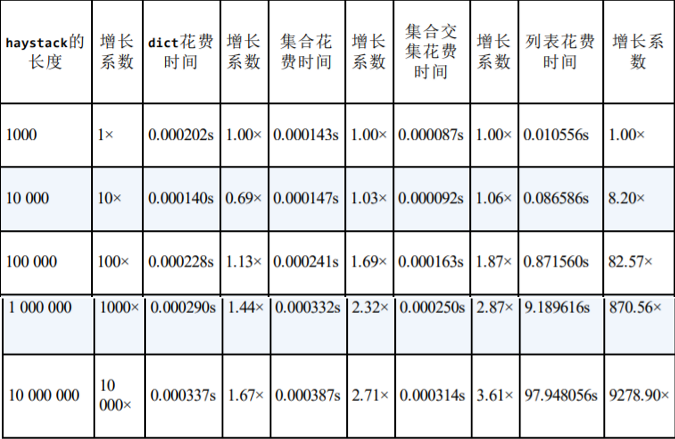
- 可以看到,当数据达到一千万的时候,字典的查询速度依旧很快
为什么有这个优势呢?
我们知道,字典维持着三分之一空表元,也就是说,字典一直有着空出来的内存。
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问。
并且,字典的散列表算法也让其在短时间内得出结果(利用hash值进行搜寻匹配即可)
得到什么,就意味着失去什么,这是很公平的一件事。
在实际情景中,只有最合适的数据结构,没有最好的数据结构。
字典推导式
最后我们谈谈生成字典的强悍方式——字典推导,这个是跟列表推导很相似的东西。
普通举例:
所谓推导式,就是使用for循环遍历可迭代对象,然后对每次循环中的变量进行更改,最后用不同容器进行存放的过程。

字典推导式也可以从任何以键值对作为元素的可迭代对象中构建出字典。对于一个承载成对数据的列表,它可以直接用在字典的构造方法中。
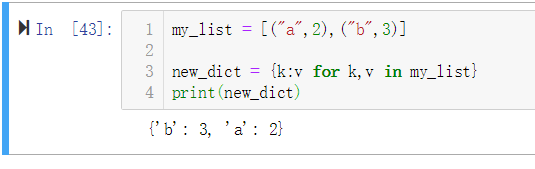
- 这涉及到了我们上篇Python进阶之序列的其他姿势中谈到的元组拆包以及结合了推导式这两个知识点。
推导式还能快速的完成一些小功能:
如果我们想要达成键值对反转的情景,可以这么做:

如果我们想在字典中对字符统计进行大小写统一,我们可以这么做:

关于python中的字典,我觉得是一个很强大的数据类型,反正我是很喜欢,哈哈~