前言
开始连载python进阶系列的博文~ 这个系列是属于掌握python基础之后的一些进阶知识,从底层出发,探索怎么实现的过程。同时,还要掌握 pythonic 的书写方式,理解python独特的魅力~ come on!
PS:因为是进阶python,因此假定读者都是具有一定python基础知识。
Python的序列类型
python 基本数据类型中,涉及序列概念的有:元组、列表、字典、字符串等等。对于不同的序列类型,我们可以将其分为两大类型:容器序列和扁平序列。
容器序列:
list、tuple 和 collections.deque 这些序列能存放不同类型的数据。
扁平序列:
str、bytes、bytearray、memoryview 和 array.array,这类序列只能容纳一种类型。
接下来我们用多个例子来展示这两种不同序列的区别.
*操作符带来的局面
我们知道 * 这个操作符可以对序列进行复制几份然后拼接。这对于不同类型的序列有着不同的效果。
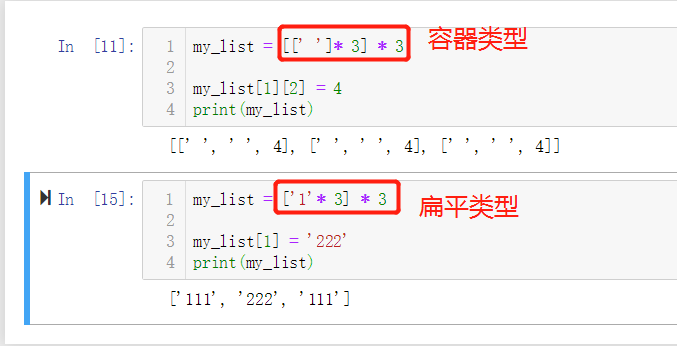
从第一个代码块可以观察发现:我们只修改了一处地方,却导致所有子列表的数值都发生了改变。这是因为容器序列存放着对象的内存地址的引用,连续乘上N次,就导致了一个问题,这些生成的元素,有了同一块内存地址的引用。可以理解为,子列表中都是对同一块内存地址的引用,当修改了引用内容时,其他指向该引用的变量也会发生改变。
但是扁平序列却不会发生这种情况,这是因为扁平序列存储的数据不是引用,而是实体数据,它对于
*操作符是这么执行的:复制所要的内容,然后去内存空间新创建一片空间,然后将复制后的内容存放进去。
区别总结:
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是实体数据而不是引用。换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
序列的增量赋值
+= 背后的特殊方法是 __iadd__。但是如果一个类 没有实现这个方法的话,Python 会退一步调用 __add__。
不过特殊方法的具体实现不在我们这篇讨论的范围之内,我们要知道的,是增量赋值对于不同序列所产生的结果。
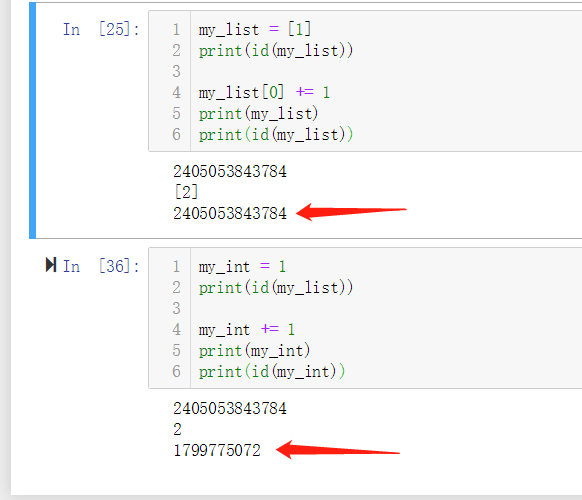
- 可以发现,整数在增量赋值之后,它的id号发生改变,而列表没有。
对于可变序列
对可变序列(例如 list、bytearray 和 array.array)来说,增量赋值会导致该序列会就地改动,就像调用了my_list.extend([1]) 一样。
对于不可变序列
而如果是不可变序列的话,从内存地址角度上看,是重新创建了一个新的对象,内容进行复制、修改,然后再指向映射。
结论:
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个 新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再修改新的元素。
但有一个例外是 str,因为对字符串做 += 实在是太普遍了,所以 CPython 对它做了优化:为 str 初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作。
讨论完不同序列的区别后,我们展开描述 python基础数据类型中元组和列表的其他姿势。
元组拆包
元组的拆包就像一把利器,会对了地方就会感觉很 pythonic。有时候,别人会告诉你:元组是不可变的列表,但元组比这有用得多。
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。
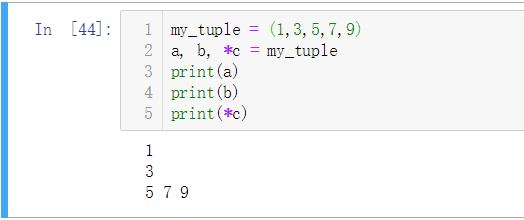
- 有了位置信息,我们可以用与元组中相同元素个数的变量进行平行赋值,这就是拆包了。
- 我们还可以利用
*号来表示多个参数(就像函数形参定义的*args一样),可以同时接收多个值
拆包的实际使用:

- os.path.split() 函数就会返回以路径和最后一个文件名组成的元组 (path,last_part):
- 在进行拆包的时候,我们不总是对元组里所有的数据都感兴趣,_ 占位符能帮助处理这种情况
列表切片
切片也是一把瑞士军刀,适用于很多种场景。它可以用来一个可迭代对象中部分的切取,拿到我们需要的内容。
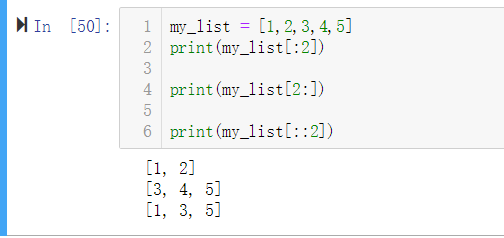
对 seq[start:stop:step] 进行求值的时候,Python 在底层会调用 seq.__getitem__(slice(start, stop, step))。
所以当一个对象没有实现__getitem__特殊方法时,是无法完成切片操作的。
切片的设计思想:
我们知道,切片是左闭右开的(包含左边,不包含右边),可为什么它的设计思想是左闭右开的呢?或者说,这么设计有什么独特的好处?
python是以0作为起始下标的,当只有最后一个位置信息时,我们可以快速看出切片和区间里有几个元素,比如:range(2) 和 list[:2] 都是返回三个元素。(而不用每次都 -1)
当起始跟结束位置都可见,我们可以快速计算出切片和区间的长度个数,用后一个数减去第一个下标(stop - start)即可。
当需要列表分割时,可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成 my_list[:x] 和my_list[x:] 就可以了(如上图行2和行4表示)
列表排序和内置排序
列表排序:
有时候我们会发现,打印排序的列表,返回的却是None:
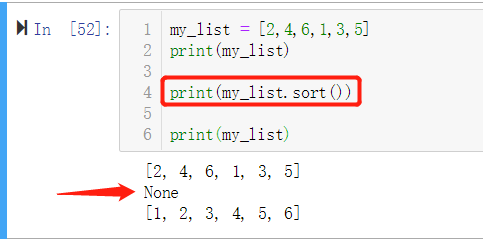
list.sort 方法会对列表本事做出排序(列表发生实际修改)。这也是这个方法的返回值是 None 的原因,这个设计是在提醒你该方法不会新建一个新列表。(实际上如果一个函数或者方法对对象进行的是就地改动,那它就应该返回None,好让调用者知道传入的参数发生了变动,而且并未产生新的对象)
内置排序:
而内置排序却恰好相反,内置函数 sorted 它会新建一个列表作为返回值。这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器。
而不管 sorted 接受的是怎样的参数,它最后都会返回一个列表。
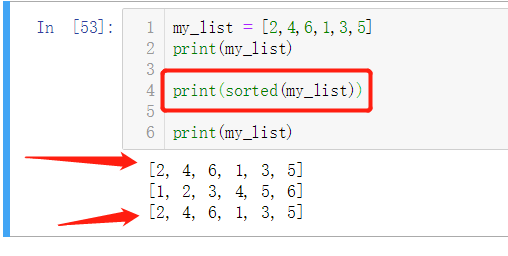
sorted是这么操作的:将可迭代对象进行复制,然后基于复制体进行排序,最后将结果返回,这意味着内置排序并没有修改可迭代对象本身。
写在最后
对于序列的一小部分总结就说到这里啦,ok,下回见!