前言
在Flask中,其本身不支持数据库。如果想要使用数据库,则需要安装插件。绝大多数的数据库都提供了Python客户端包,它们之中的大部分都被封装成Flask插件以便更好地和Flask应用结合。数据库被划分为两大类:关系数据库和非关系数据库。
在Flask中,关于数据库的插件是Flask-SQLAlchemy,这个插件为流行的SQLAlchemy包做了一层封装以便在Flask中调用更方便,类似SQLAlchemy这样的包叫做Object Relational Mapper,简称ORM。 ORM允许应用程序使用高级实体(如类,对象和方法)而不是表和SQL来管理数据库。 意思就是说:ORM的工作就是将高级操作转换成数据库命令,我们只需编写高级的逻辑就行了。
SQLAlchemy不只是某一款数据库软件的ORM,而是支持包含Mysql、SQLite、PostgreSQL等数据库软件。很多教学都是采用SQLite,而我想使用Mysql 进行开发(不过也可以在开发的时候使用简单易用的SQLite,需要部署应用到生产服务器上时,则选用更健壮的MySQL或PostgreSQL服务)
Flask-SQLAlchemy配置
首先,安装插件:
1 | (venv) $ pip install flask-migrate |
然后,我们在config.py文件中添加以下配置项:
1 | import os |
- Flask-SQLAlchemy插件从
SQLALCHEMY_DATABASE_URI配置变量中获取应用的数据库的位置。 - 我们这里直接指定了mysql,然后键入账号密码@主机 / 数据库名
- 由于使用的是Mysql数据库,在应用运行之前,需要先将数据库(这里的flask_demo2)进行创建。
接着,app/__init__.py文件变更如下:
1 | from flask import Flask |
- SQLAlchemy类传入一个app(可以是多个数据库,所以要指明具体是哪一个应用),然后实例化出来的db是数据库对象。
- migrate是数据库迁移对象,我们以后在数据库中的变更都是基于它进行操作的。
数据库模型
定义数据库中一张表及其字段的类,通常叫做数据模型。ORM(SQLAlchemy)会将类的实例关联到数据库表中的数据行,并翻译相关操作。接下来完成我们之前说的数据库模型代码实现:
1 | from app import db |
- User类继承自db.Model,它是Flask-SQLAlchemy中所有模型的基类。User被称为”模型“,而不是表明。
- 这个类将表的字段定义为类属性,字段被创建为
db.Column类的实例,它可以传入字段类型以及其他可选参数 - 该类的
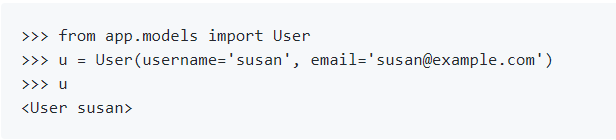
__repr__方法用于在调试时打印用户实例。(更友好的打印,如下图)
数据库迁移技术
在实际情况中,随着应用的不断增长,很可能会新增、修改或删除数据库结构。如果没使用数据库迁移技术的话,我们只能使用删表重建的方法,这导致了一个严重的后果:表数据清零。
这在实际使用肯定是无法忍受的缺陷,于是我们需要有一种技术来替代这种”笨方法“。
Alembic(Flask-Migrate使用的迁移框架)将以一种不需要重新创建数据库的方式进行数据库结构的变更。它是这么实现的: 每当对数据库结构进行更改后,都需要向存储库中添加一个包含更改的详细信息的迁移脚本。 当应用这些迁移脚本到数据库时,它们将按照创建的顺序执行。
初始化数据库
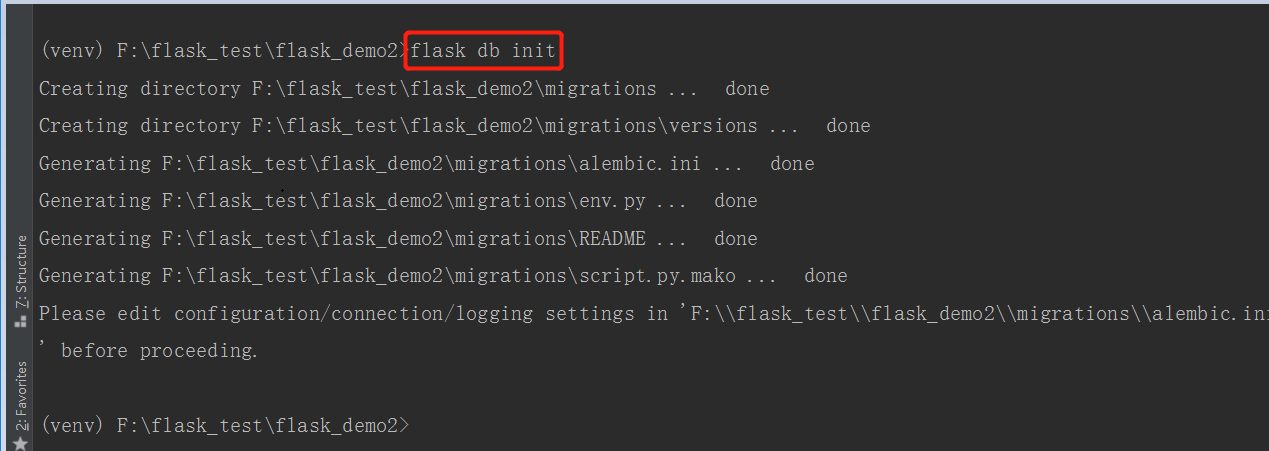
- 运行迁移初始化命令之后,你会发现一个名为migrations的新目录。该目录中包含一个名为versions的子目录以及若干文件。从现在起,这些文件就是你项目的一部分了,其负责代码版本管理(类似git的机制,详见我写的另一篇文章:Git入门指引)。
数据库迁移
包含映射到User数据库模型的用户表的迁移存储库生成后,是时候创建第一次数据库迁移了。
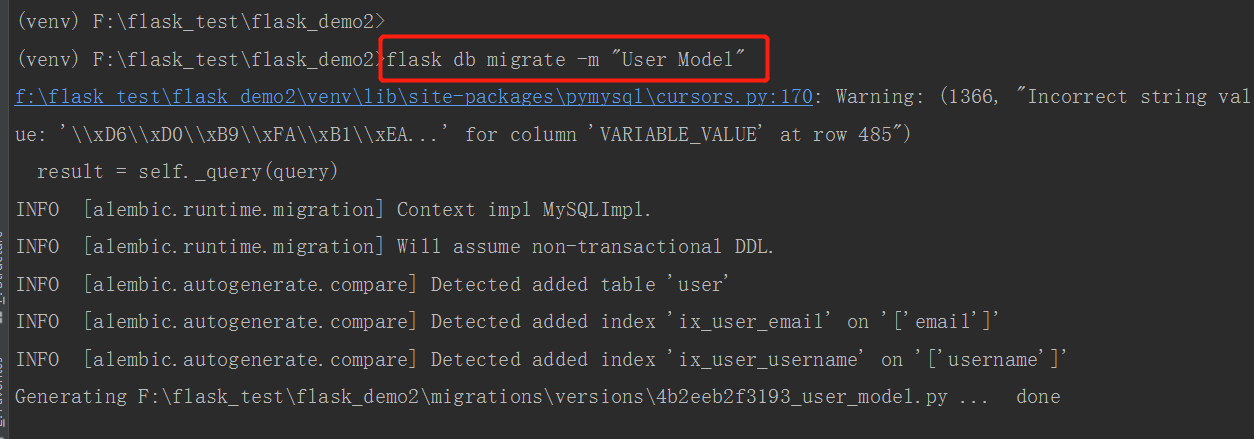
-m可选参数为迁移添加了一个简短的注释。(相当于log的作用)- 生成的迁移脚本现在是你项目的一部分了,需要将其合并到源代码管理中。
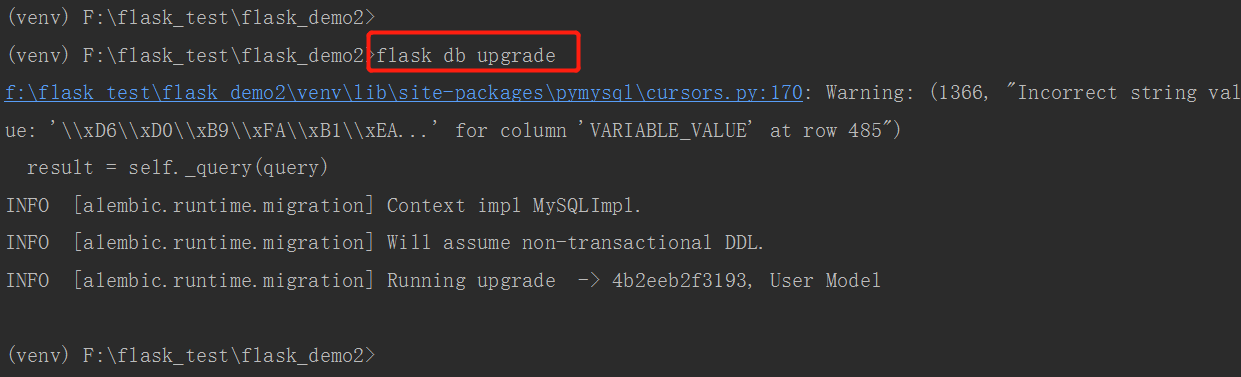
flask db migrate命令不会对数据库进行任何更改,只会生成迁移脚本。 要将更改应用到数据库,必须使用flask db upgrade命令。
应用到数据库
数据库关系
对于关系型数据库来说,更难的是表关系的定义。我们已经有了User表,如果想要定义一张post表,同时想要实现类似查询一个用户发布了多少文章的语句,应该如何实现呢?
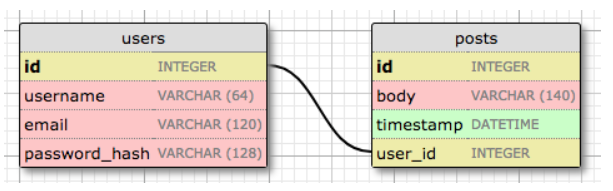
莫慌, Flask-SQLAlchemy有助于实现这种查询。post表将具有必须的id、用户动态的body(内容)和timestamp(发布日期)字段。 除了这些预期的字段之外,我还添加了一个user_id字段,将该用户动态链接到其作者。
这种关系被称为一对多,因为“一个”用户写了“多”条动态。
修改后的app/models.py如下:
1 | from datetime import datetime |
User类有一个新的posts字段,用db.relationship初始化。这不是实际的数据库字段,而是用户和其动态之间关系的高级视图,因此它不在数据库图表中。对于一对多关系,db.relationship字段通常在“一”的这边定义,并用作访问“多”的便捷方式。db.relationship的第一个参数表示代表关系“多”的类。backref参数定义了代表“多”的类的实例反向调用“一”的时候的属性名称。 这将会为用户动态添加一个属性post.author,调用它将返回给该用户动态的用户实例。
这里,我们变动了数据库的结构,所以要进行数据库迁移操作:migrate和upgrade
写在最后
数据库的相关操作就是这些啦,主要的还是关系数据库中表的创建和字段的引用。其他的学会之后套用即可。