前言
我们在之前介绍如何解析响应数据时讲到了 BeautifulSoup 这个解析库,传送门: 爬虫Day6-Beautiful介绍
但学习之后我们发现,BeautifulSoup 是依赖解析器的,在实际开发环境中,我们常常遇到一些特殊情况,例如编码格式导致解析时发现页面数据缺失等等情景。
这时候,除了更换解析器这个办法之外,我们还可以使用其他的解析库,例如 Xpath。
Xpath介绍
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言(XML也是一种标签化语言)。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
Python 标准库中自带了 xml 模块,但是性能不够好,而且缺乏一些人性化的 API,相比之下,第三方库 lxml 是用
Cython 实现的,而且增加了很多实用的功能,可谓爬虫处理网页数据的一件利器。lxml 大部分功能都存在
lxml.etree中。
Xpath 常用规则
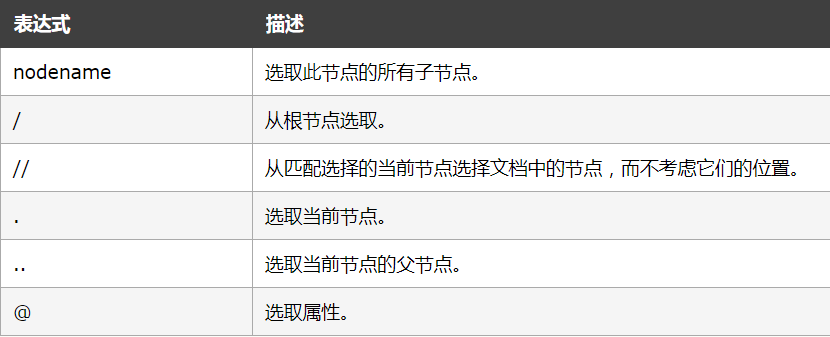
- 每一条 / 都表示一层嵌套关系,我们需要对HTML结构进行一定的了解,使用Xpath 才更加得心应手
- // 匹配的节点好比喻成文件系统的绝对路径,如果有相符的节点名称,那么就会被匹配到
- @ 这个符号选取属性,我们一般用来获取 URL ,例如:@href
下面列出用法举例:

LXML 库 的使用
读入HTML 文本
1 | from lxml import etree |
- 传入 HTML 文本,会自动修正(补齐缺漏的节点标签)且生成一个XPath解析对象,后续的解析都是根据解析对象来调用xpath方法进行节点选择
- 由于初始化 HTML 文本返回的结果是bytes类型,我们打印出来时,需要转为utf-8。
读入HTML 纯文件
1 | from lxml import etree |
- test.html是我们创建的html文件,里面存放一些html文本
- 跟直接读取html文本不同的是,文件读取会多出 DOCTYPE 的声明,但是对内容解析没有影响
- tostring 方法 可以实现 将 内容结构化打印出来(比较直观)
xpath 选择节点
关于怎么选择节点,除了上面讲的 xpath 常用规则之外,还有一些关于 属性匹配、属性获取的使用方法。
1 | from lxml import etree |
- 属性获取:@href 即可获取节点的 href 属性
- 属性匹配:使用中括号,@属性名 = 值 的方式来限定某个属性
获取文本
用 XPath 中的 text() 方法可以获取节点中的文本
1 | result6 = html.xpath('//li[@class ="item-0"]/a/text()') #获取a节点下的内容 |
- 这里要注意,text()方法要结合着前面的”/“或“//” 标签看,如果是 “/” 的话,就输出当前子节点的文本;如果是 “//” 的话,就输出当前节点的所有子孙节点的文本
模糊查询
如果 HTML 文本中的 li 节点的 class 属性有两个值 ,例如 “class =li li-first”
遇到这种情况,我们可以用contains()函数或者将多个值写全,才能匹配到该节点。
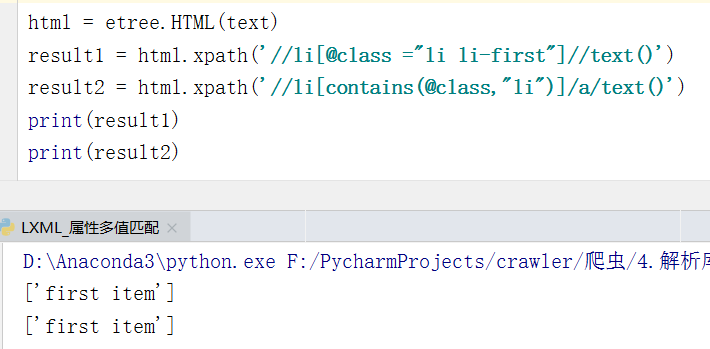
多属性匹配
如果需要根据多个属性才能确定一个节点,这是就需要同时匹配多个属性才可以,那么这里可以使用运算符 and 来连接(xml还支持其他运算符)

- and 表示 “与” 的关系,只有同时满足两个属性匹配表达式,该节点才会被选中。
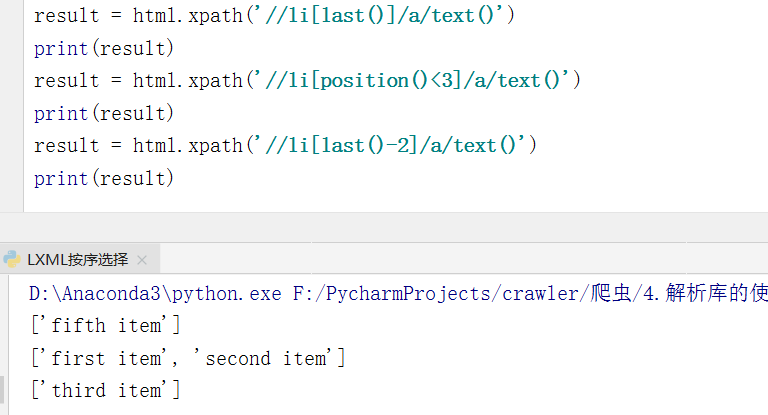
按序选择
有时候我们在选择的时候可能某些属性同时匹配了多个节点,但是我们只想要其中的某个节点,如第二个节点,或者最后一个节点,这时该怎么办呢?
这时可以利用中括号传入索引的方法获取特定次序的节点
类似于列表的切片,不过需要注意:
- 这里的切片的索引是从1开始的
- 支持last、position等函数
- 还支持+-<>的推算
写在最后
这一篇还是干货满满的,哈哈哈,慢慢吸收吧~ 关于节点选择的编写,写熟了自然就会了。
下回见,peace~