前言
关于数据存储,我们之前已经讲了数据库的存储: 爬虫Day7-Mysql的那些事 ,还有 爬虫Day13-Mongodb存储
但是对于一些小型的文件,我们可以使用多种格式类型的文件保存到本地,相对于数据库来说,比较便捷。今天介绍的是有关文件数据存储的相关内容。
文本存储
将数据保存到 TXT 文本的操作非常简单,而且 TXT 文本几乎兼容任何平台,但是有个缺点就是不利于检索,所以如果对检索和数据结构要求不高,追求方便第一的话,可以采用 TXT 文本存储。
1 | import requests |
我们在上面做了以下事情:
- 请求网页(设置headers头部)
- 发出get请求,获得网页响应内容
- 观察网页内容,调用解析库,传入获取的html文本,生成doc对象
- 使用选择器进行内容匹配
- 写入文件(优化数据)
需要注意的是,构造文件句柄的时候,需要注意编码问题,同时,文件的处理类型也要指明(默认是“r”)
媒体文件存储
存储媒体文件的两种方式:
只获取文件 URL 链接
直接把源文件下载下来
对于爬虫来说,如果我们要爬取的东西很多,那么建议使用第一种方式。使爬虫运行得更快,耗费的流量更少,因为只要链接,不需要下载文件。
那么,如果通过URL链接,下载我们想要的媒体文件呢?
urllib的urlretrieve方法
在python3 中, urllib.request.urlretrieve 可以根据文件的 URL 下载文件:
1 | from urllib.request import urlretrieve |
urlretrieve方法传入两个参数:
- 下载的URL链接,以及所保存的文件名
- 注意文件后缀名要和保存的数据相符合,例如 图片是jpg格式,那么我们传入的文件名后缀也要是 jpg 格式
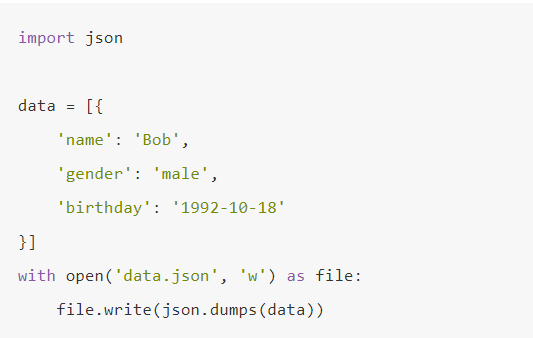
Json 文件存储
Json,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,它是一种轻量级的数据交换格式。
Python 为我们提供了简单易用的 json 库来供我们实现 Json 文件的读写操作,我们可以调用 json 库的 loads() 方法将已编码的 JSON 字符串解码为 Python 对象,可以通过 dumps()方法将 Python 对象编码成 JSON 字符串。
值得注意的是 Json 的数据需要用双引号来包围,不能使用单引号。
并且,如果存储的数据中包含中文,我们需要指定一个参数 ensure_ascii 为 False,另外规定文件输出的编码(不指定文件输出的编码会乱码)
读取Json
读取:使用 loads() 方法,将Json对象解码为 Python 对象

存储Json
调用 dumps() 方法将 Python 对象编码成 JSON 字符串。
CSV文件存储
CSV,全称叫做 Comma-Separated Values,中文可以叫做逗号分隔值或字符分隔值。通俗的讲,他就是就是以特定字符分隔的纯文本,我们可以使用 Excel 打开 .csv的文件。单调、简朴是这种文件类型的风格。
CSV的写入

- 首先打开了一个 data.csv 文件,然后指定了打开的模式为 w,即写入,获得文件句柄。
- 随后调用 csv 库的 writer() 方法初始化一个写入对象,传入该文件句柄,然后调用 writerow() 方法传入每行的数据即可完成写入。
- 第一行通常是存储字段的字段名,这起到标识字段值的作用。
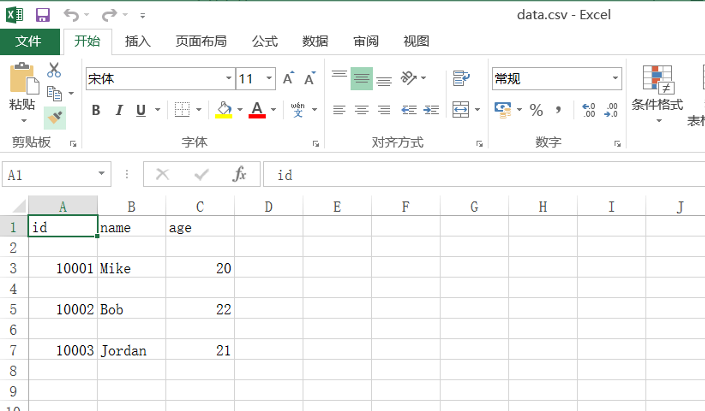
文件打开效果如下:
CSV的读取
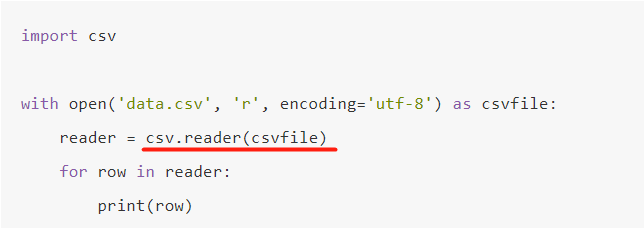
- 关于如何打开
.CSV后缀的文件,并不是在 open()返回的 File 对象上调用 read()或 readlines()方法,而是将 File 对象传递给 csv.reader()函数。这将返回一个 Reader对象。我们将基于此对象进行文件读取。 - 同时,我们可以使用 for 循环遍历出文件内容。
线上CSV
Python 的 csv 库主要是面向本地文件,就是说你的 CSV 文件得存储在你的电脑上。而我们进行网络数据采集的时候,很多文件都是在线的。不过有几种方法可以解决这个问题:
- 手动把 CSV 文件下载到本机,然后用 Python 定位文件位置;
- 写 Python 程序下载文件,读取之后再把源文件删除;
- 从网上直接把文件读成一个字符串,然后转换成一个 StringIO 对象,使它具有文件的属性。
虽然前两个方法也可以用,但是既然你可以轻易地把 CSV 文件保存在内存里,就不要再下载到本地占硬盘空间了。可以直接把文件读成字符串,然后封装成*StringIO对象,让Python把它当作文件来处理,就不需要先保存成文件了。
代码实现:
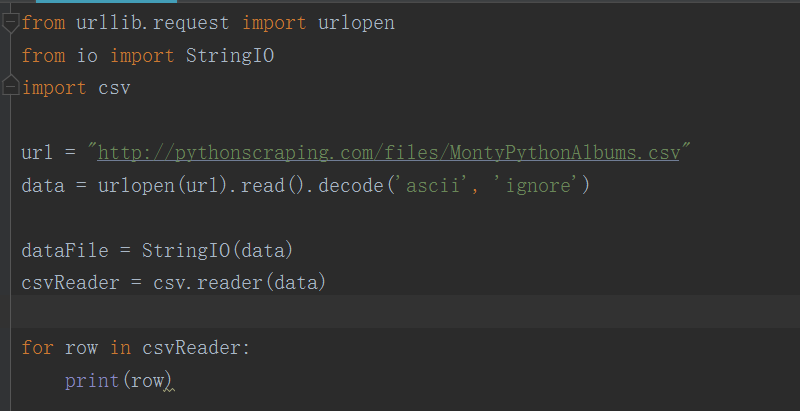
- 跟读取本地CSV 文件步骤相似,只是多了使用 StringIO( )方法将在线的CSV文件转为StringIO对象。
- 这样就实现了线上 CSV 的文件读取,是不是很方便!
写在最后
ok了,这一篇我们介绍了关于文件存储的大部分流行技术,快快用起来吧~
朋友们,下回见啦。