前言
上一篇的模拟登陆 爬虫Day14-模拟登陆Github 提到,具体的反爬手段还有验证码,而验证码又分为很多类:图形验证码、极验滑动验证码、点触验证码等等。对于简单的验证码,我们可以利用脚本识别,如果是比较复杂的验证码,建议外接到打码平台,省时省力。
今天我们要讲的是图形验证码。

环境准备
识别图形验证码需要库 tesseract 和 Pillow。请自行百度安装。
Pillow 是从 Python 图像库(Python Imaging Library,PIL)分出来的;而关于tesseract,在python中它的库为tesserocr。
有人分不清为什么安装了软件还要安装模块,其实是这样的:在python 中的库相当于软件的包装器,可以帮助我们调用软件。
tesseract 的使用
我们先保存一张验证码到本地,用来测试使用。名为 code.jpg
如下图:

第一种方法:
1 | import tesserocr |
- 通过两行代码我们就将验证码识别出来,是不是很棒!
第二种方法:
1 | import tesserocr |
运行结果如下:
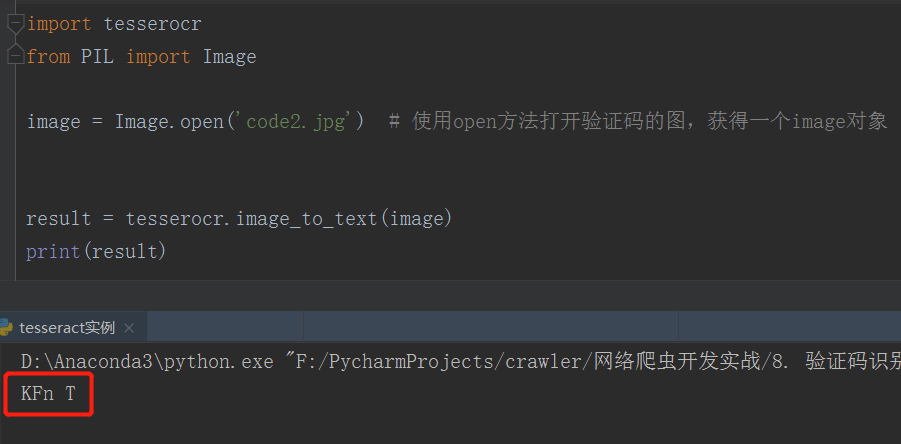
- 可以看到多出来个空白格,对于一些复杂的线条,tesseroct库会识别失效,这个我们后面会说。
- 并且,第二种方法是基于打开图片后的image对象进行操作的,而且识别效果更高。建议采用第二种写法噢~
转灰度、二值化
上面的方法虽然快捷、但是一旦遇到有复杂线条干扰的验证码,识别准确度就会大大下降。我们可以通过转灰度、二值化进行加工处理,让图片变得更容易电脑识别。
先了解一下这个convert 方法:
convert():将当前图像转换为其他模式,并且返回新的图像。
代码实现:
1 | import tesserocr |
利用Image对象的convert()方法参数传入’L’,即可将图片转化为灰度图像
传入数字”1” 即对图片进行二值化处理,convert()方法采用的是默认阈值为127。不过我们不能直接转化原图,要将原图先转为灰度图像,然后再指定二值化阔值
threshold 变量存储的二值化阈值的规律是:数值越低接近白,越高越黑(并且是从左到右渲染的)
images.point方法:返回给定查找表对应的图像像素值的拷贝。变量table为图像的每个通道设置256个值。
它会为输出图像指定一个新的模式(mode指定的模式)
转灰度、二值化的变化过程:

- 可以看到,一些复杂的线条就被我们清理掉了,剩下白色背景、黑色字体的图片(tesseroct最喜欢这个了)
运行结果:
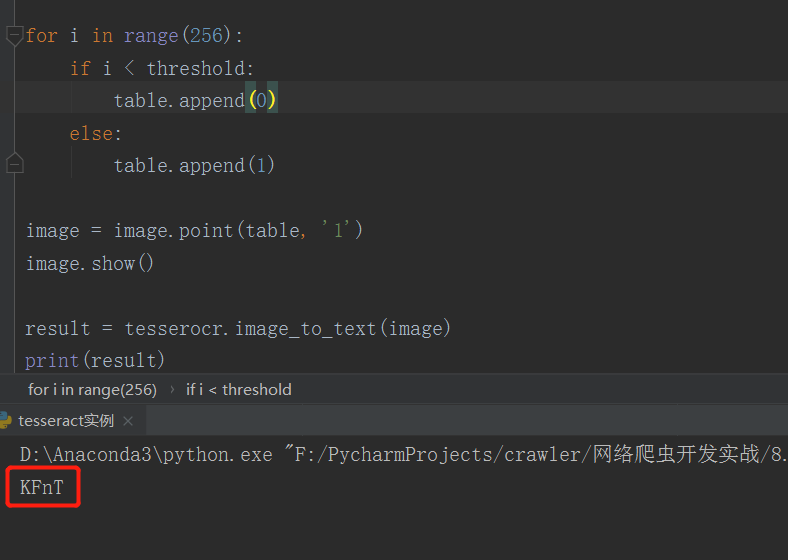
- 经过后期处理之后,现在的识别准确度大大提高,对于此张验证码,我们做到了完美识别!
写在后面
验证码绝对是反爬工程师手中的一把利器,可以阻挡住多数低级爬虫。
这篇只是介绍了下图形验证码,对于验证码,还需要其他方面知识的铺垫、例如机器学习、一定的数学基础等等。
当你学会识别大多数的验证码时,就可以自信的去敲BAT级别公司的门了。
