前言
B站可谓是个资源丰富的地方,对我来说,它就是一个学习网站,里面啥都有。。。我们今天使用selenium 爬取B站信息,实现 关键词 抓取 的需求。
对于selenium 我们之前已经介绍过: 爬虫Day8-Selenium魔法师
实战
url = https://www.bilibili.com/
使用 selenium ,当然是先需要获取我们对应点击的节点,进行模拟操作了。
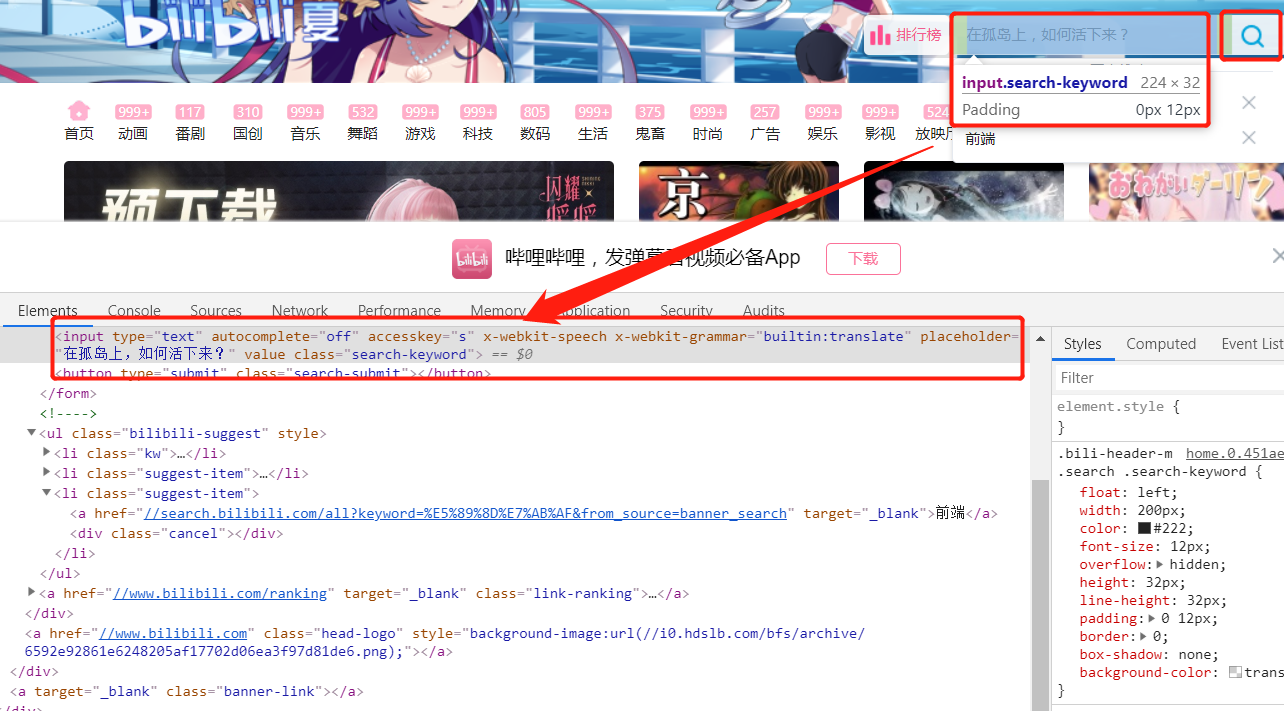
拿着之前的文章,这不是小意思嘛,欻欻的写出了下面这段代码:
代码v1.0
1 | from selenium import webdriver |
ok…接着我们运行一下代码测试一下,然后就来到了这个页面
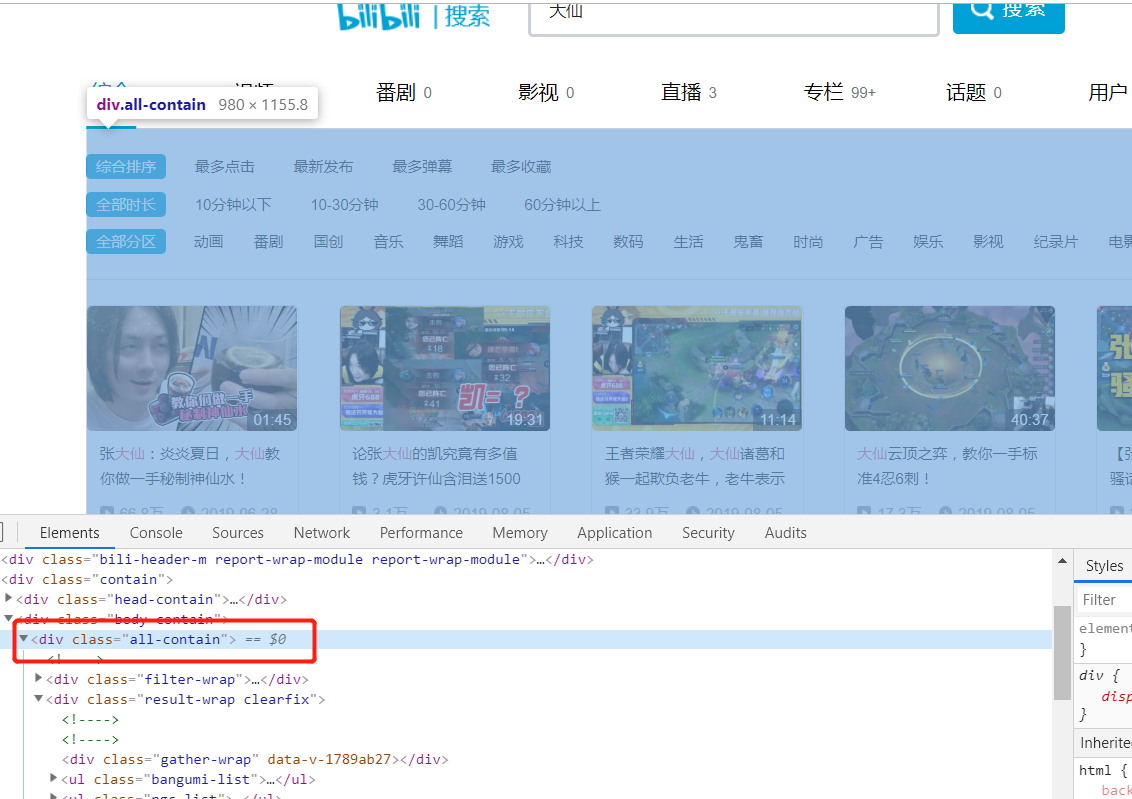
- 发现所有的视频内容都包括在一个 class = “all-contain”的 div 中
- 我们使用 find 方法将其匹配出来。
代码v1.1
1 | def get_page(): |
- 为什么有一个页面跳转的步骤呢? 因为啊,我们的浏览器发送关键词搜索之后,页面已经切换了,而我们后续需要使用page_source 属性获取响应信息,如果没有页面切换,那么得到的响应内容是原页面的内容,这不是我们想要的。
解析
我们调用 爬虫Day6-Beautiful介绍 这个库 进行代码解析并写入文件
1 | def parser(html): |
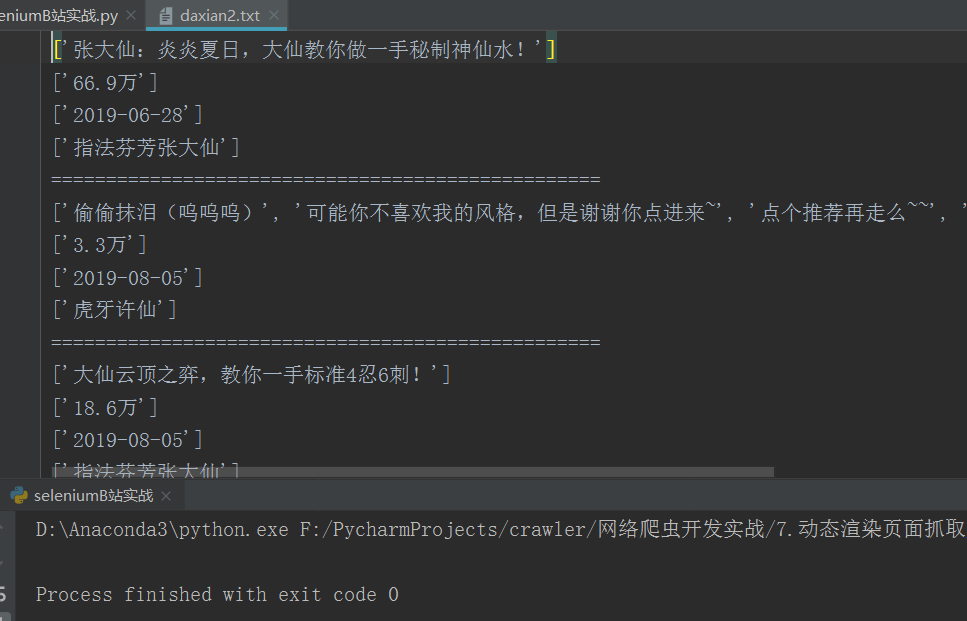
运行结果如下:
后记
这一次的selenium实战就介绍到这里了, 如果想实现多页爬取,同样道理,利用 EC.element_to_be_clickable() 显示等待 “下一页”节点加载出来,然后模拟点击即可。
用没用感受到selenium的魅力呢? 什么反爬什么加密统统不在话下!这可不是吹的~
