Ajax引言:
有时候我们在用 Requests 抓取页面的时候,得到的结果可能和在浏览器中看到的是不一样的,在浏览器中可以看到正常显示的页面数据,但是得到的 Response 并没有相应的内容。
这其中的原因是 Requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是页面又经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种:
- 通过 Ajax 加载
- 包含在了 HTML 文档中的(我们之前爬取的网站都是这个类型)
- 经过 JavaScript 经过特定算法计算后生成的。
1 | 今天我们就来谈谈 Ajax 加载类型的网页数据。 |
Ajax的概念
Ajax,全称为Asynchronous JavaScript and XML,即异步的 JavaScript和 XML, 对于Ajax 渲染 的页面,数据的加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后会会再向服务器请求某个接口获取数据,然后数据再被处理才呈现到网页上,这其实就是发送了一个 Ajax请求。
这也就是我们直接使用 requests 请求 不到页面实际内容的原理所在。
这时需要做的就是分析网页的后台向接口发送的 Ajax 请求,再用Requests 来模拟 Ajax 请求,那就可以成功抓取了。

1 | 知道了A jax 原理之后,一切就变得有头绪了些~ |
Ajax 观察
对于Ajax 请求, 我们在现实生活中一直碰到,我描述一下你就知道了:“当你在浏览网页、APP的时候,下拉进度条到最下面时,会看到进度条唰的一下子跳到中间,然后下方有了新的内容出现”
其实这就是Ajax 的运用了。
今天,我们使用 微博来作为爬取对象。
url = https://m.weibo.cn/u/2145291155
浏览器发起请求
老规矩,进入开发者模式。 然后在Network 下,点击 XHR 进行筛选(过滤出只有Ajax请求的请求响应报文)
让我们看第一个条目信息,观察其Response
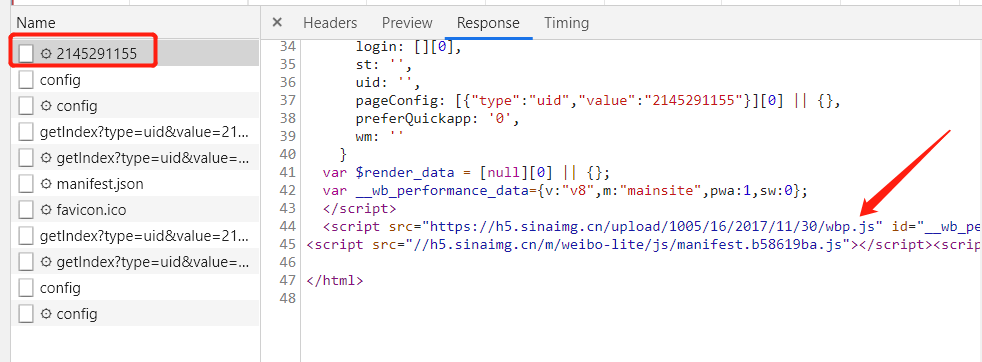
发现其代码只有五十行,结构也非常简单,只是执行了一些 JavaScript。这只是最原始的链接返回的结果。
所以说,我们所看到的微博页面的真实数据并不是最原始的页面返回的,而是后来执行 JavaScript 后再次向后台发送了 Ajax 请求,拿到数据后再进一步渲染出来的。
于是我们进行测试,拖拽进度条到最下面,发现浏览器与服务器偷偷的交互了报文,效果如下:
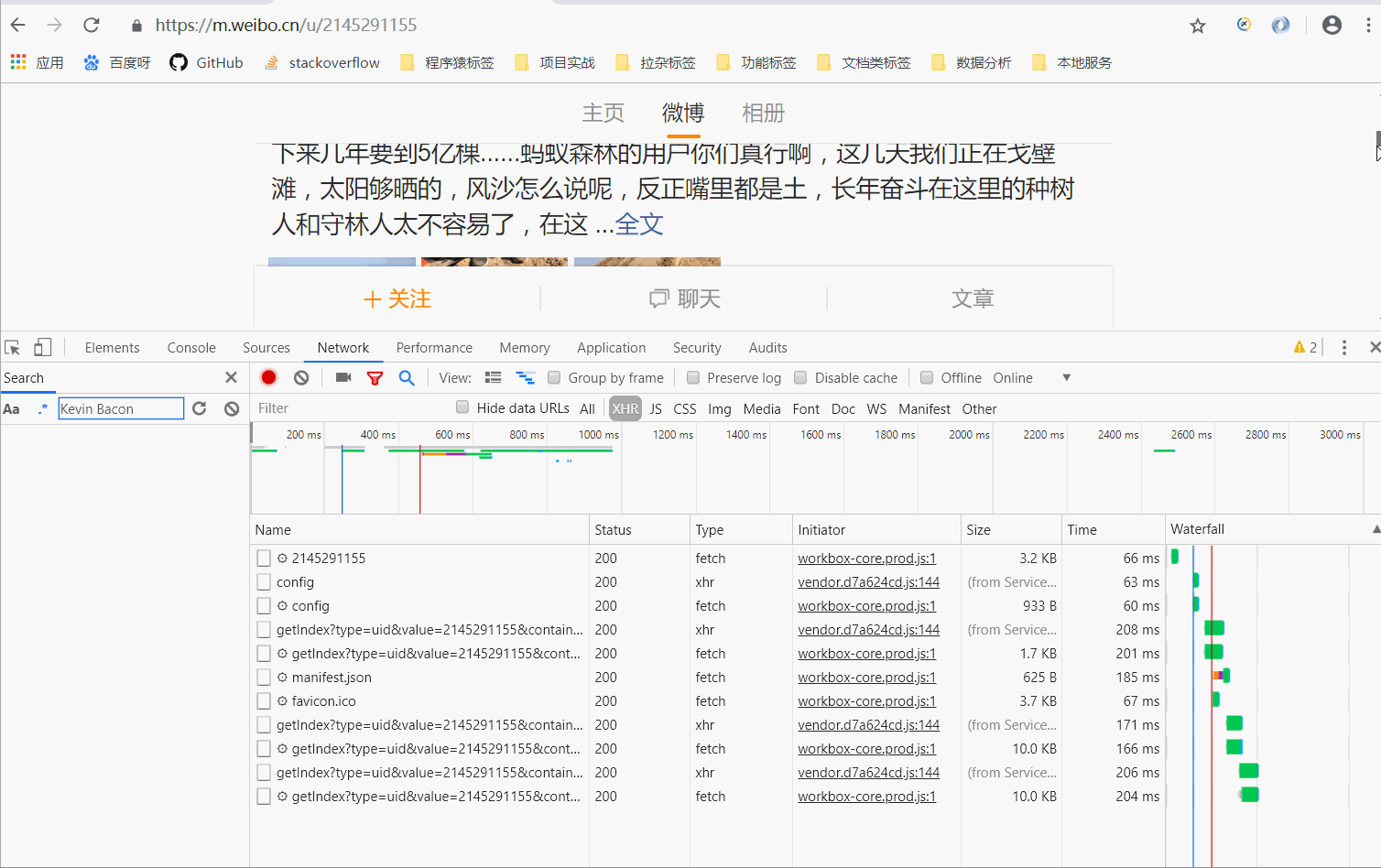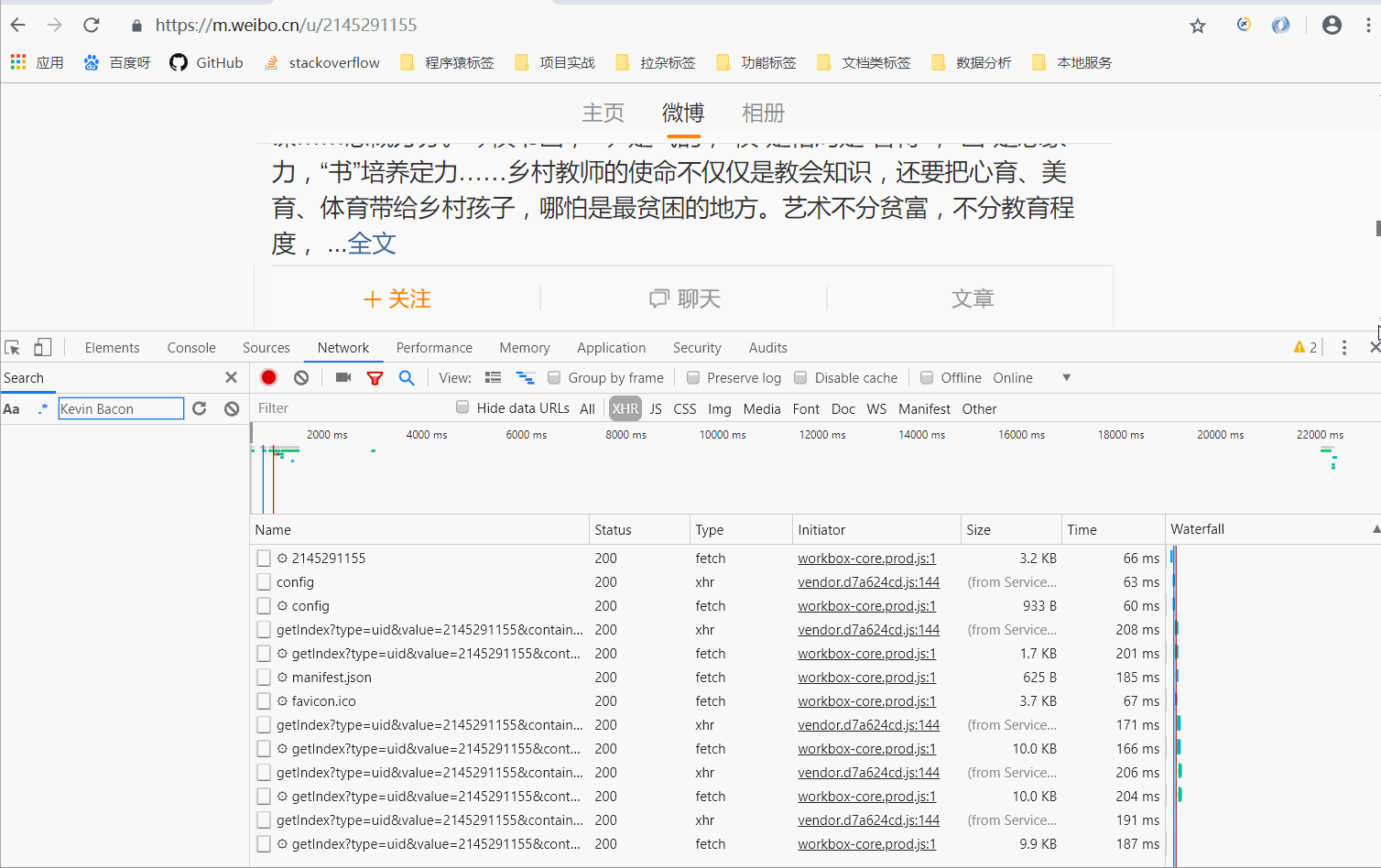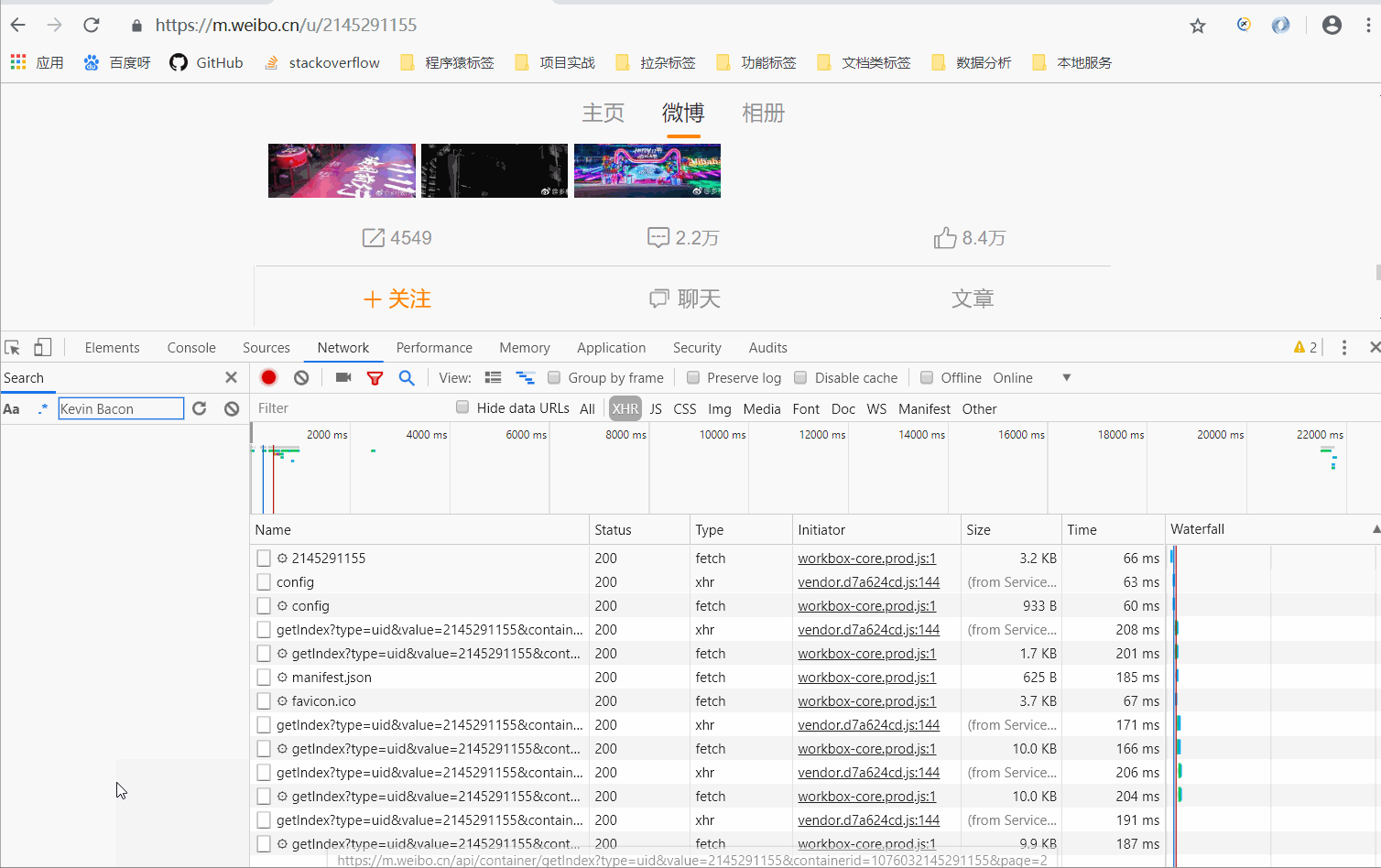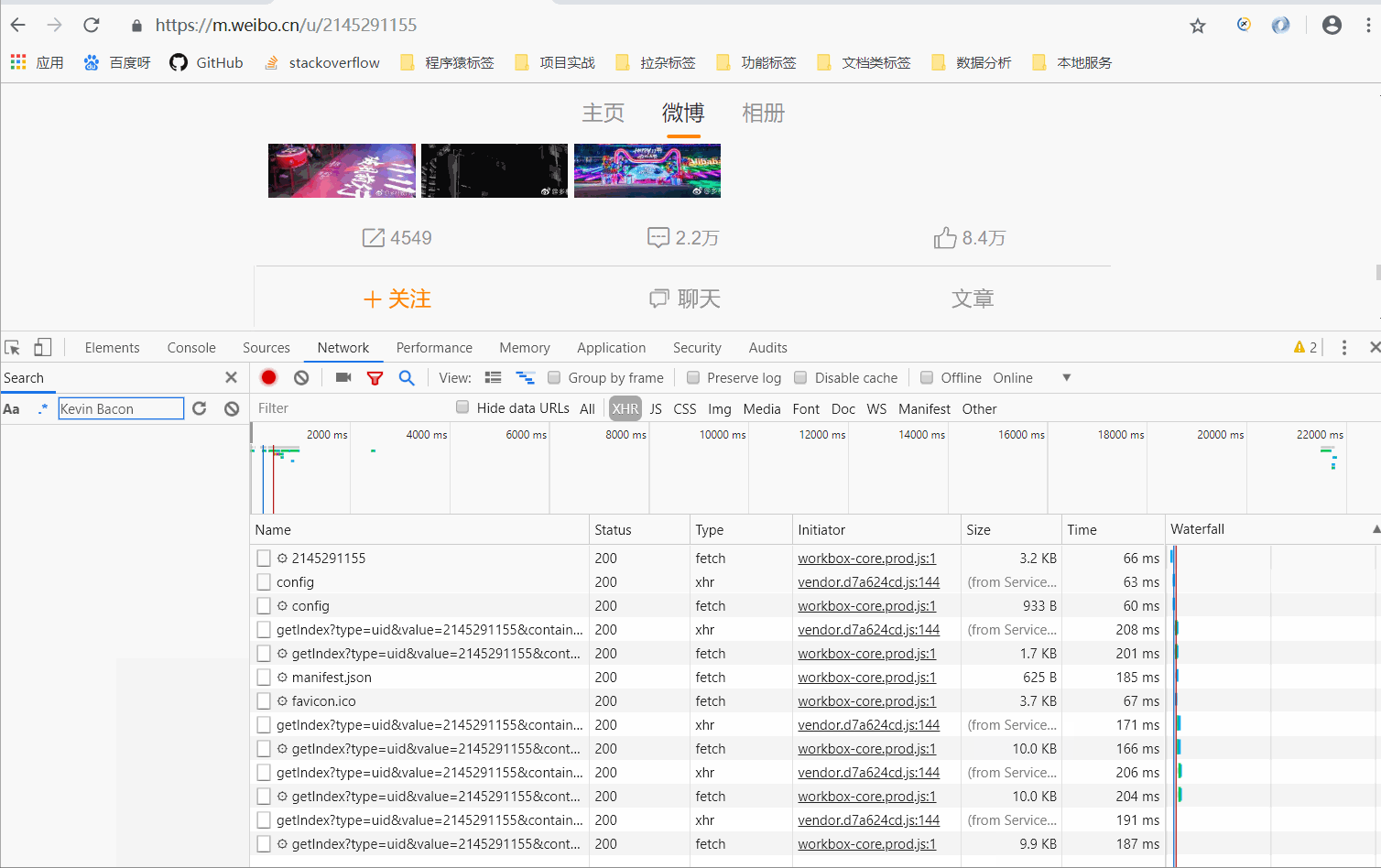
- 新刷新出来的响应报文就是网站下方一些新的内容了
- Ajax 渲染网页的就是这样,当用户看到下方时,才会加载内容。这样在 Web 开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。(以后可能都是这样类型的网页噢,赶紧学起来吧~)
查看详细信息
我们点开这条响应报文进行分析。
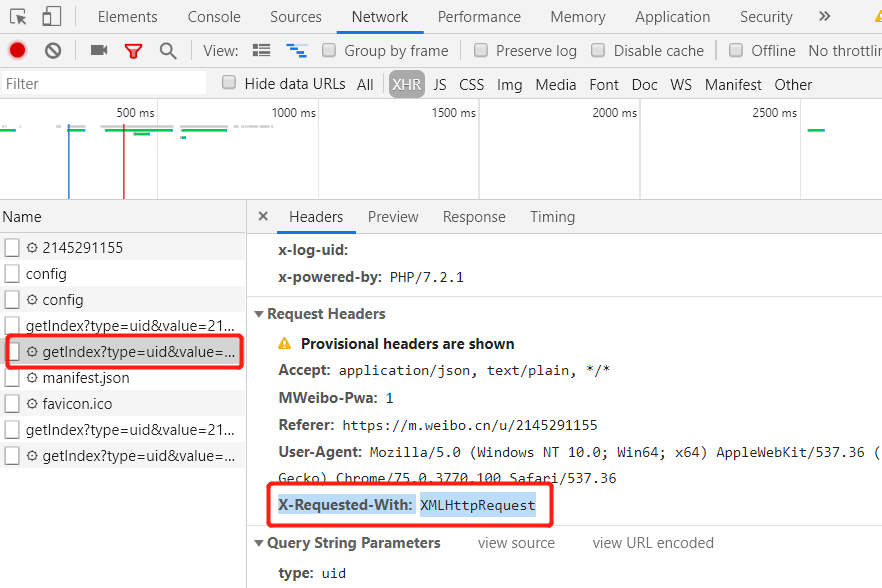
Ajax其实有其特殊的请求类型,它叫作xhr。我们可以发现一个名称以getlndex开头的请求,其Type为xhr,这就是一个Ajax请求。
其中RequestHeaders 中有一个字段为 X-Requested-With:XMLHttpRequest,这就标记了此请求是Ajax异步请求
Ajax 结果提取
我们要能将Ajax内容提取出来,就是要用Python来模拟这些Ajax请求,达到自动加载页面信息的功能。(第一步就是观察参数的规律,这是解析网页的必修课)
① URL的构建
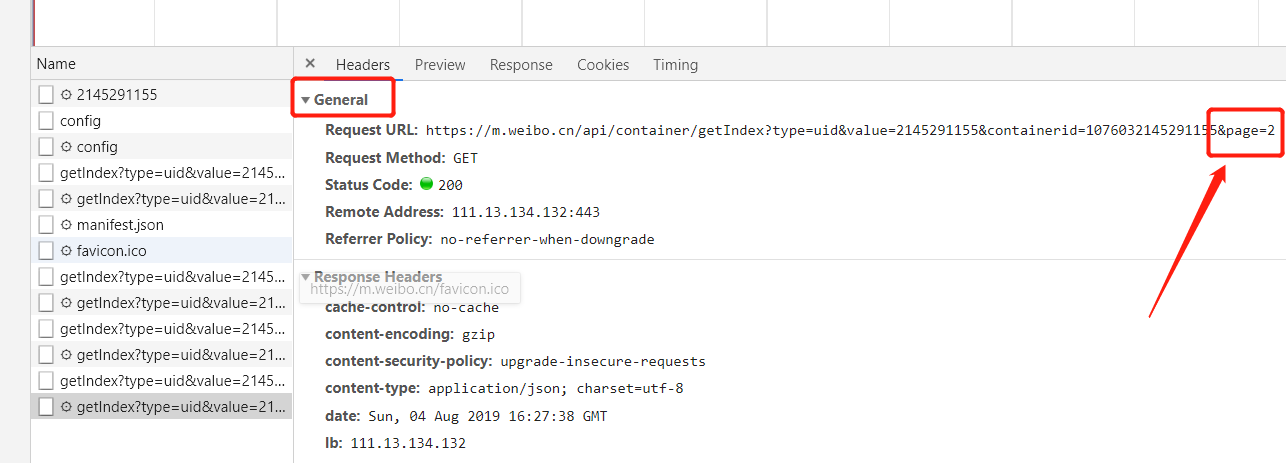
- 观察一下这些请求,发现它们的 type、value、containerid 始终如一。type 始终为 uid,value 的值就是页面的链接中的数字,其实这就是用户的 id,另外还有一个containerid,经过观察发现它就是 一个常量 然后加上用户id。
- 所以改变的值就是 page,很明显这个参数就是用来控制分页的,page=1 代表第一页,page=2 代表第二页,以此类推。我们使用一个变量来控制页码数
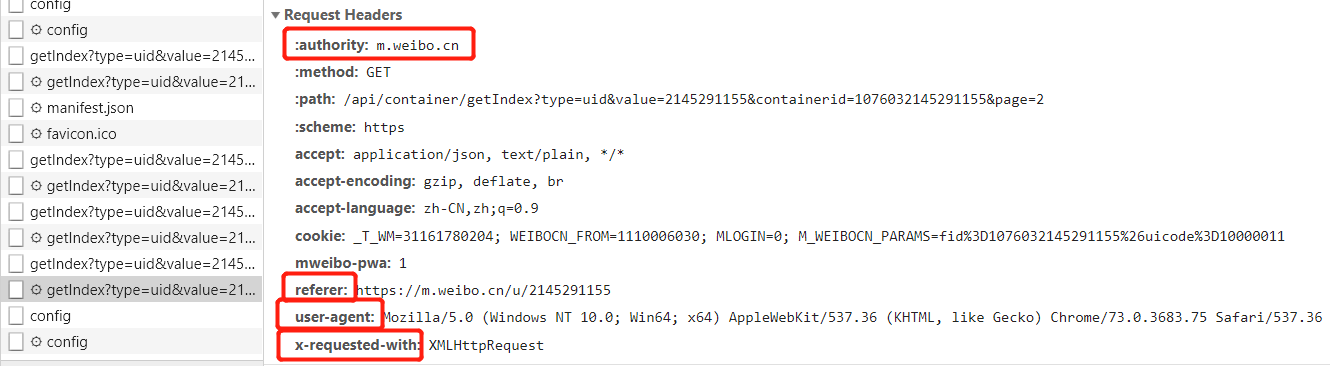
② 头部的构造
并且,我们需要构造header头部,模拟这是由浏览器发出的Ajax请求,还有一些重要字段(最基本的反爬策略)
③ 观看响应内容
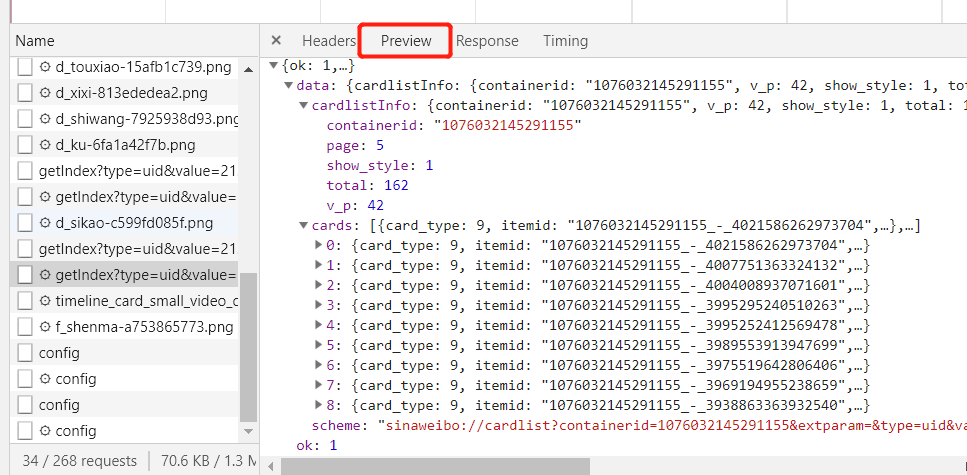
- 它是一个 Json 格式,浏览器开发者工具自动为做了解析方便我们查看,可以看到最关键的两部分信息就是 cardlistInfo 和 cards,将二者展开,cardlistInfo 里面包含了一个比较重要的信息就是 total,经过观察后发现其实它是微博的总数量,我们可以根据这个数字来估算出分页的数目。
- 其中cards 则是一个列表,它包含了 10个元素,这就是每一条微博帖子存放的地方所在了。
④我们继续展开看看

- 发现它包含的正是微博的一些信息。比如 attitudes_count 赞数目、comments_count 评论数目、reposts_count 转发数目、created_at 发布时间、text 微博正文等等
Python 代码模拟
1 | import requests |
运行结果如下:
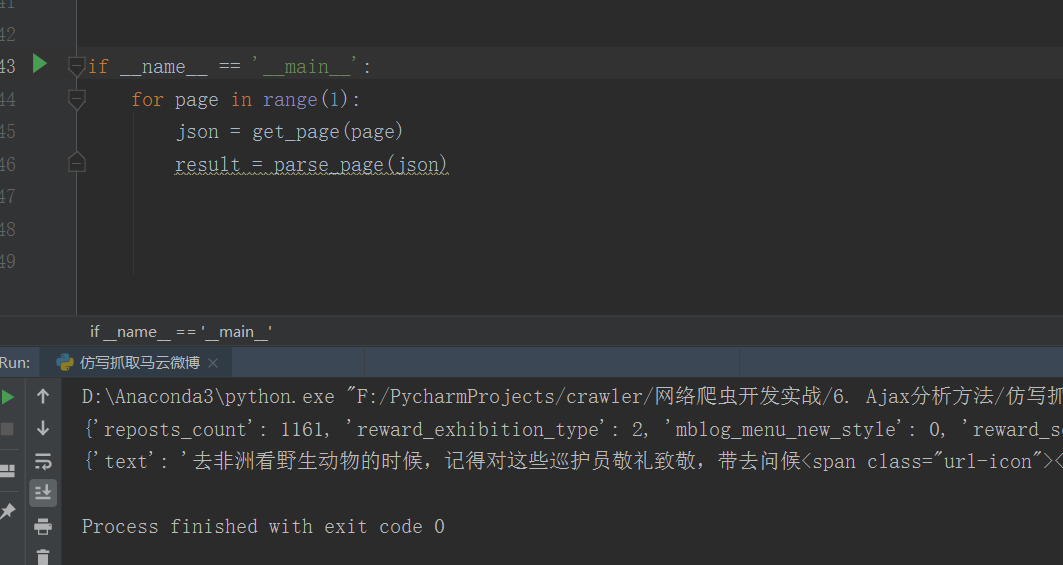
- 先抓取一页进行测试,完成!
- 这样,我们只需要增加 变量 page,即可将微博数据全部爬取下来了。由于篇幅原因,略过。
写在后面:
这次我们主要介绍了Ajax 请求的原理,这样一来,我们就可以模拟Ajax请求,对任何使用异步加载的网页进行爬取了。
啊~ 溜了溜了,胖友们,我们下回见。