前言
久违的爬虫Day 系列!! 自从计算机网络系列更新完之后,我又把目光投到爬虫系列来了hhh… 今天介绍的技术可厉害了,在外人眼中,这近乎是“魔法”,那就是——selenium
同时,这也是我目前最为喜欢的爬取工具。
Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。用 Selenium 来驱动浏览器加载网页的话,我们就可以直接拿到 JavaScript 渲染的结果了,不管是什么加密统统不用再需要担心。
环境准备:
selenium
Chrome浏览器 与 ChromeDriver
以上内容,请自行百度安装
selenium介绍:
模拟登陆:
声明浏览器对象:
selenium 驱动浏览器进行操作的,于是我们要实例化一个浏览器对象,有以下:

接下来我们要做的就是调用 生成的 browser 对象,让其执行各个动作,就可以模拟浏览器操作了。
访问页面:
基于browser对象, 我们可以用 get() 方法来请求一个网页,参数传入链接 URL 即可(get方法没有返回值,他只是模拟了浏览器的运行)
1 | from selenium import webdriver |
让我们看看效果:
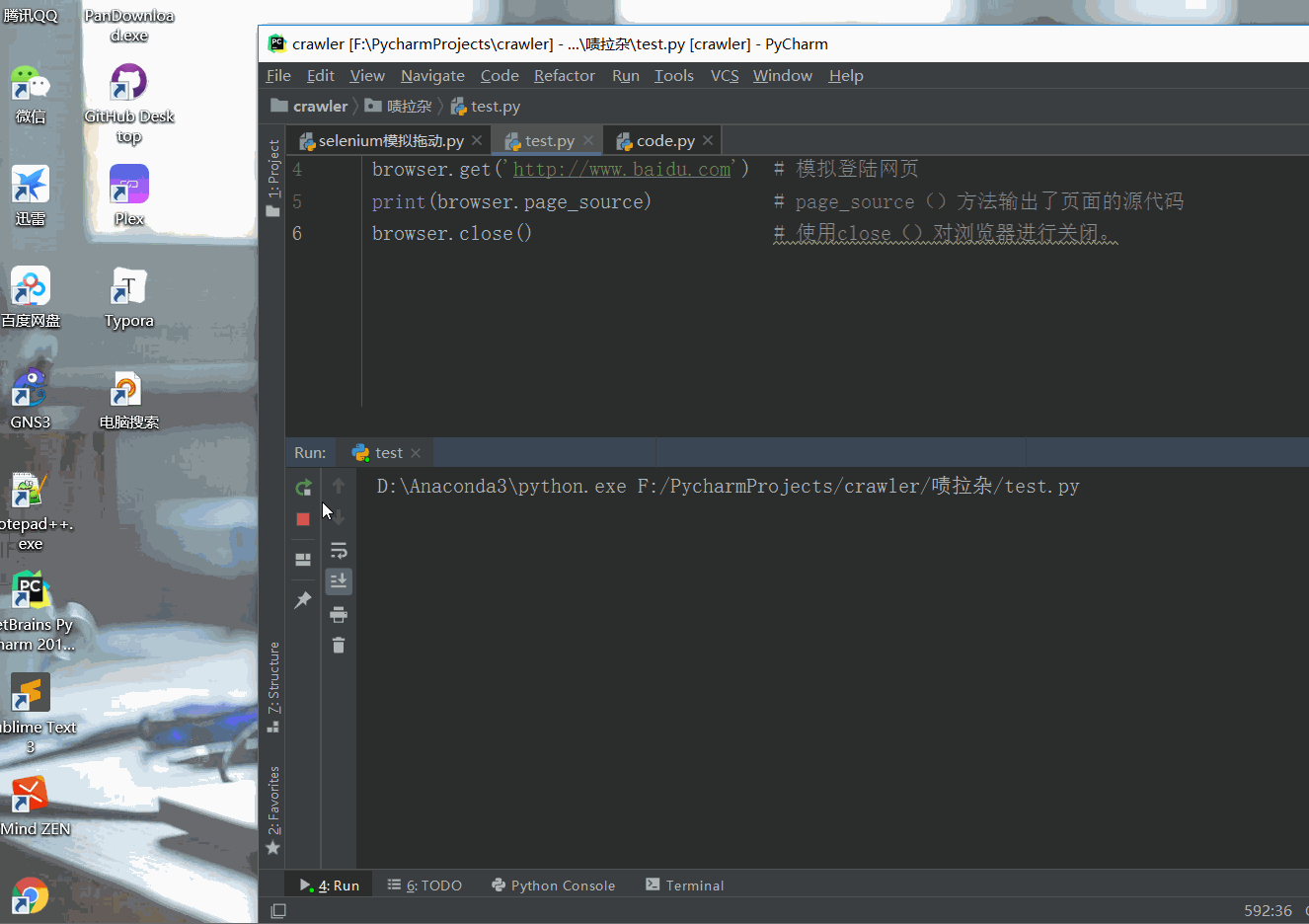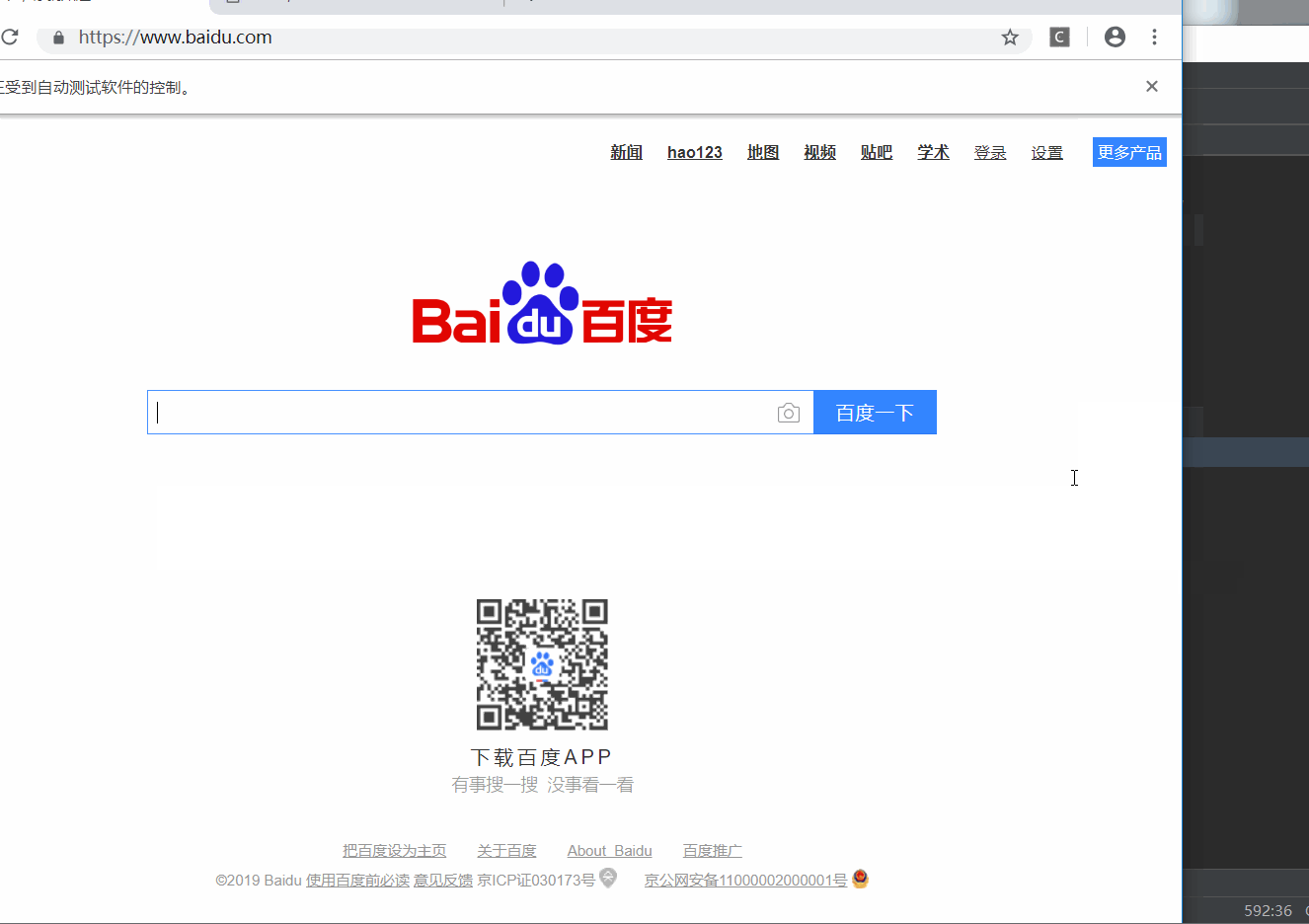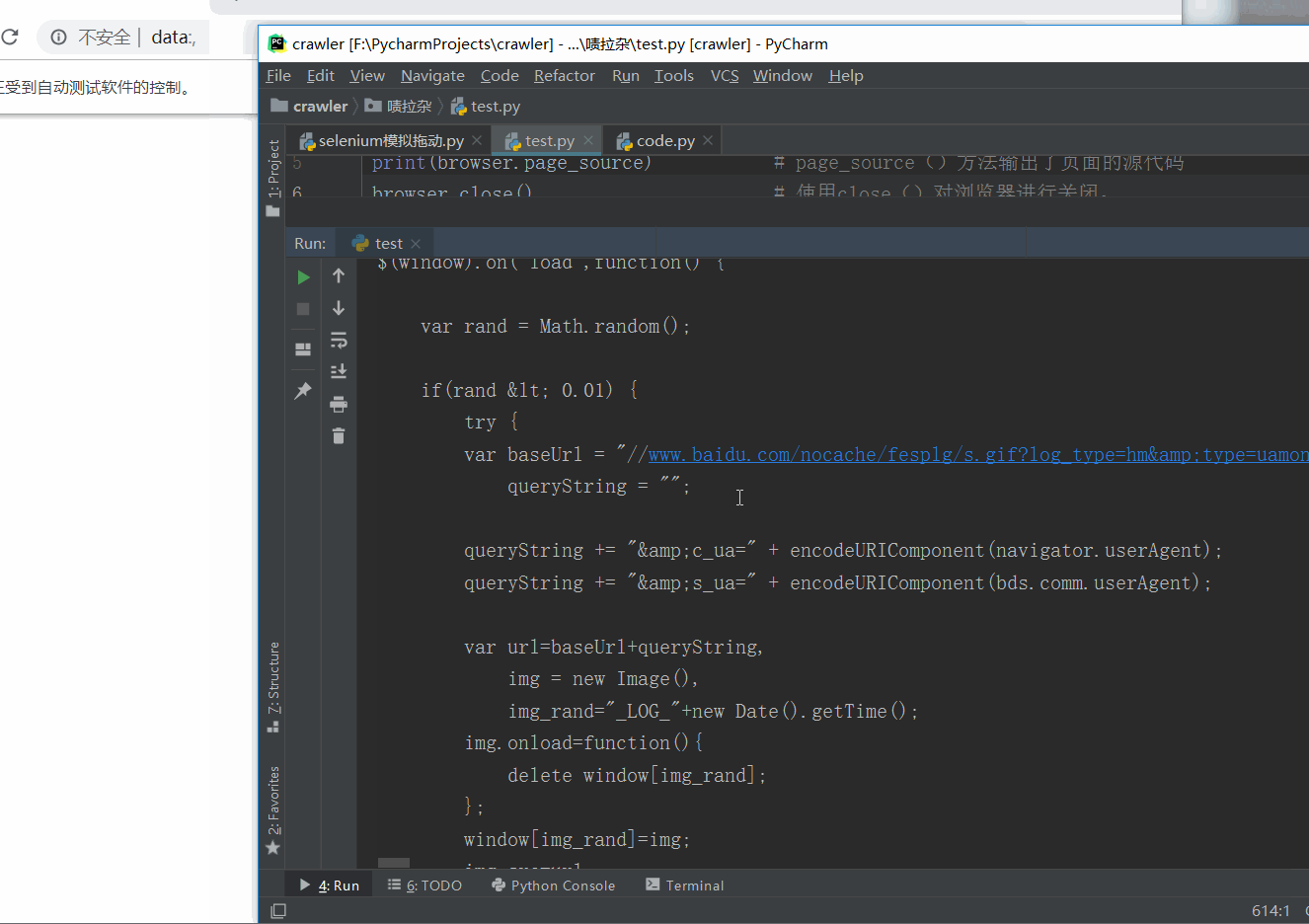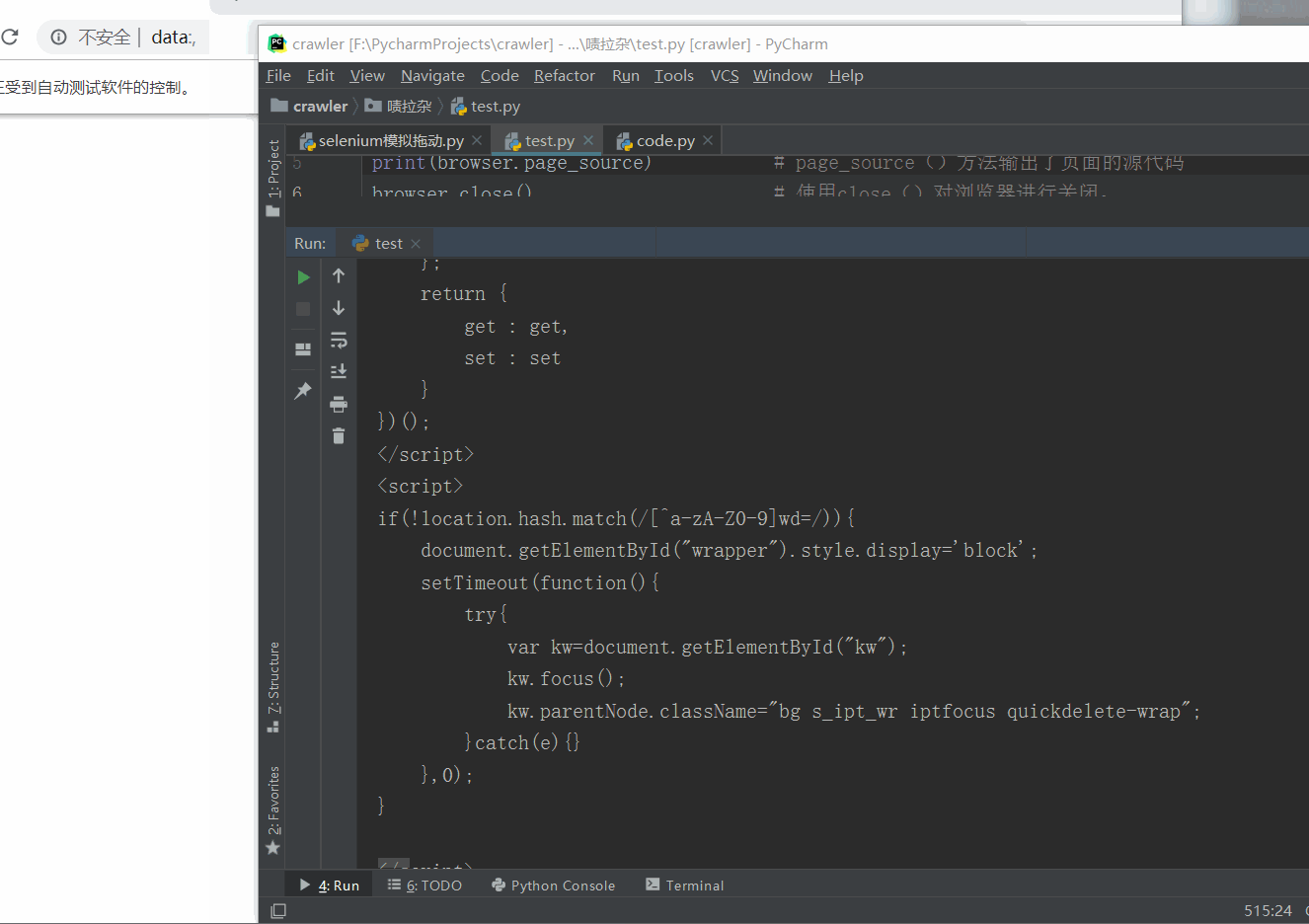
有没有看到嗖的一下子,就访问了百度这个网站,然后解析出了HTML。
注意: 这里我们拿到了一个 browser 对象,这个在后续操作中,是最关键的(节点选择,动作交互等等,都是基于 browser对象进行操作)

查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等等,比如我们想要完成向某个输入框输入文字的操作,在这这前我们需要得知这个输入框的位置。
所以 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便于下一步执行一些动作或者提取信息。
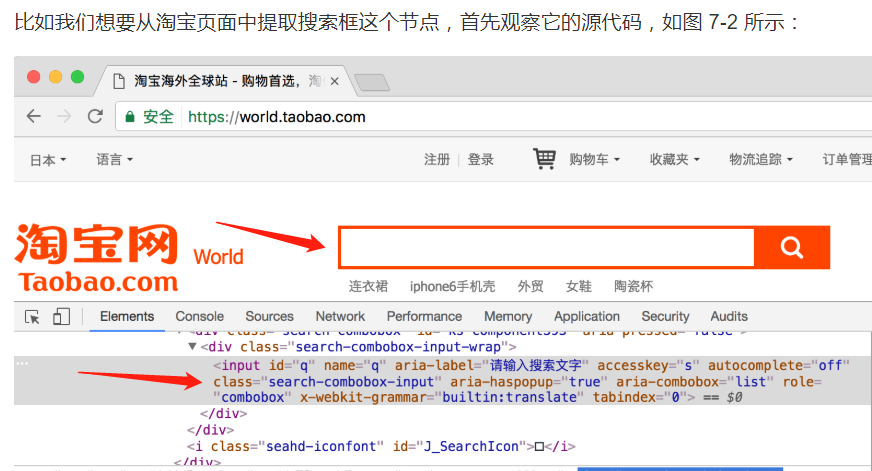
- 我们想要驱动浏览器完成自动搜索的任务,首先要先找到文本输入框。图中
<input>节点就是我们要找的目标,熟悉前端的胖友,肯定倍感亲切。 - 可以发现它的 ID 是 q,Name 也是 q,还有许多其他属性,那我们获取它的方式就有多种形式了,第一种是通过节点名称查找,比如find_element_by_name() 是根据 Name 值获取,find_element_by_id()是根据 ID 获取,另外还有根据XPath、CSS Selector 等获取的方式。
以下代码可以查找出文本框的节点:
1 | from selenium import webdriver |
效果演示:
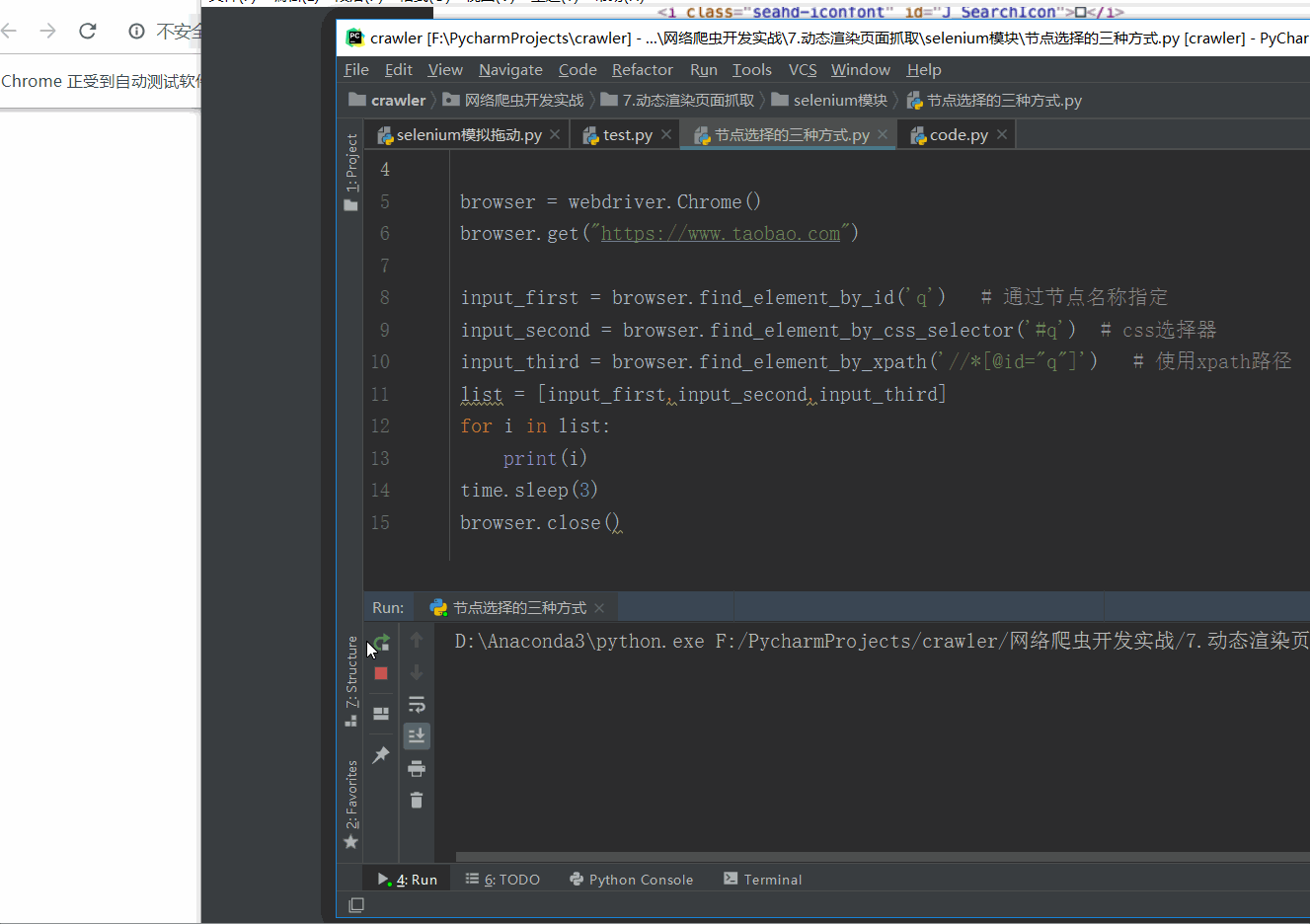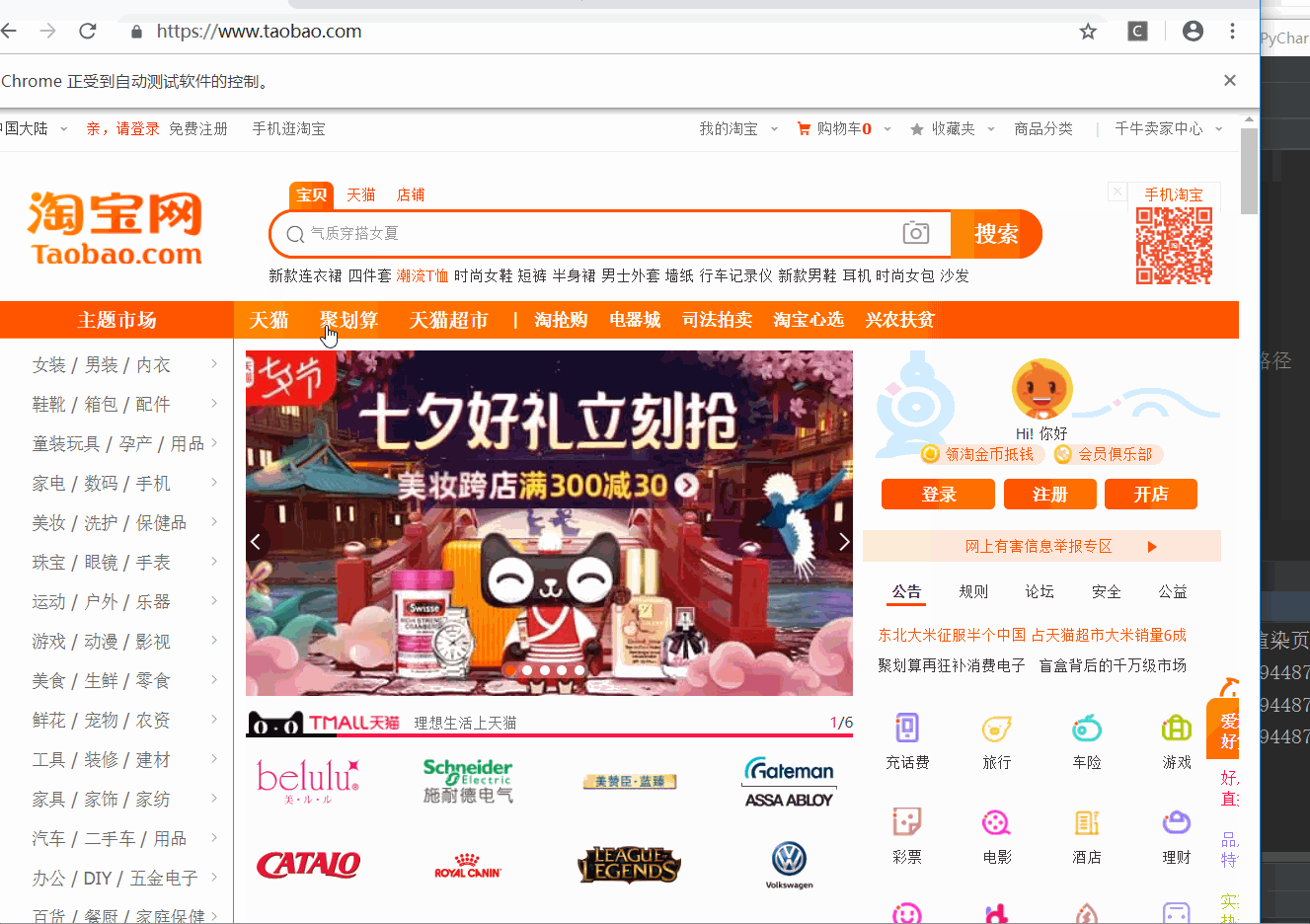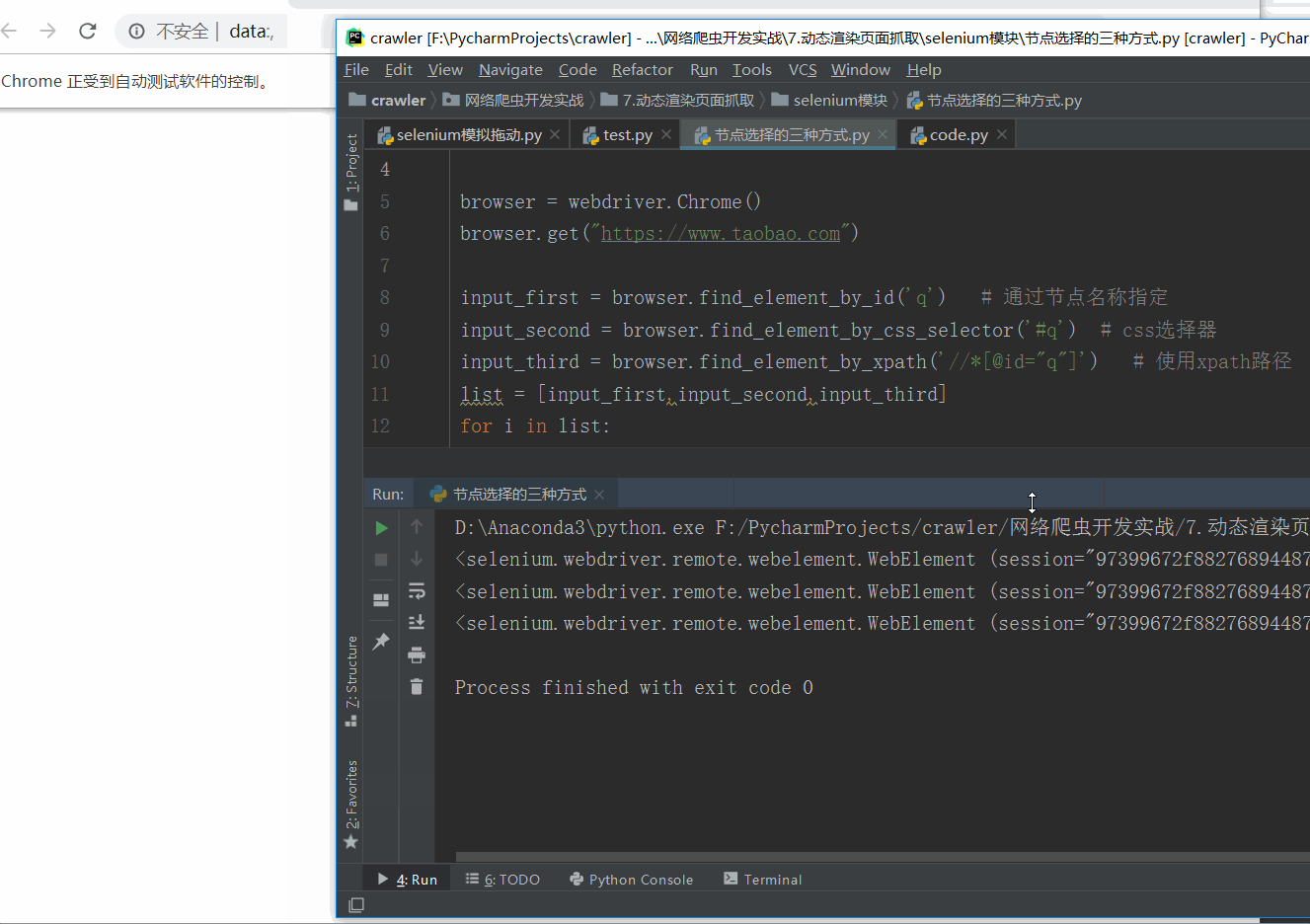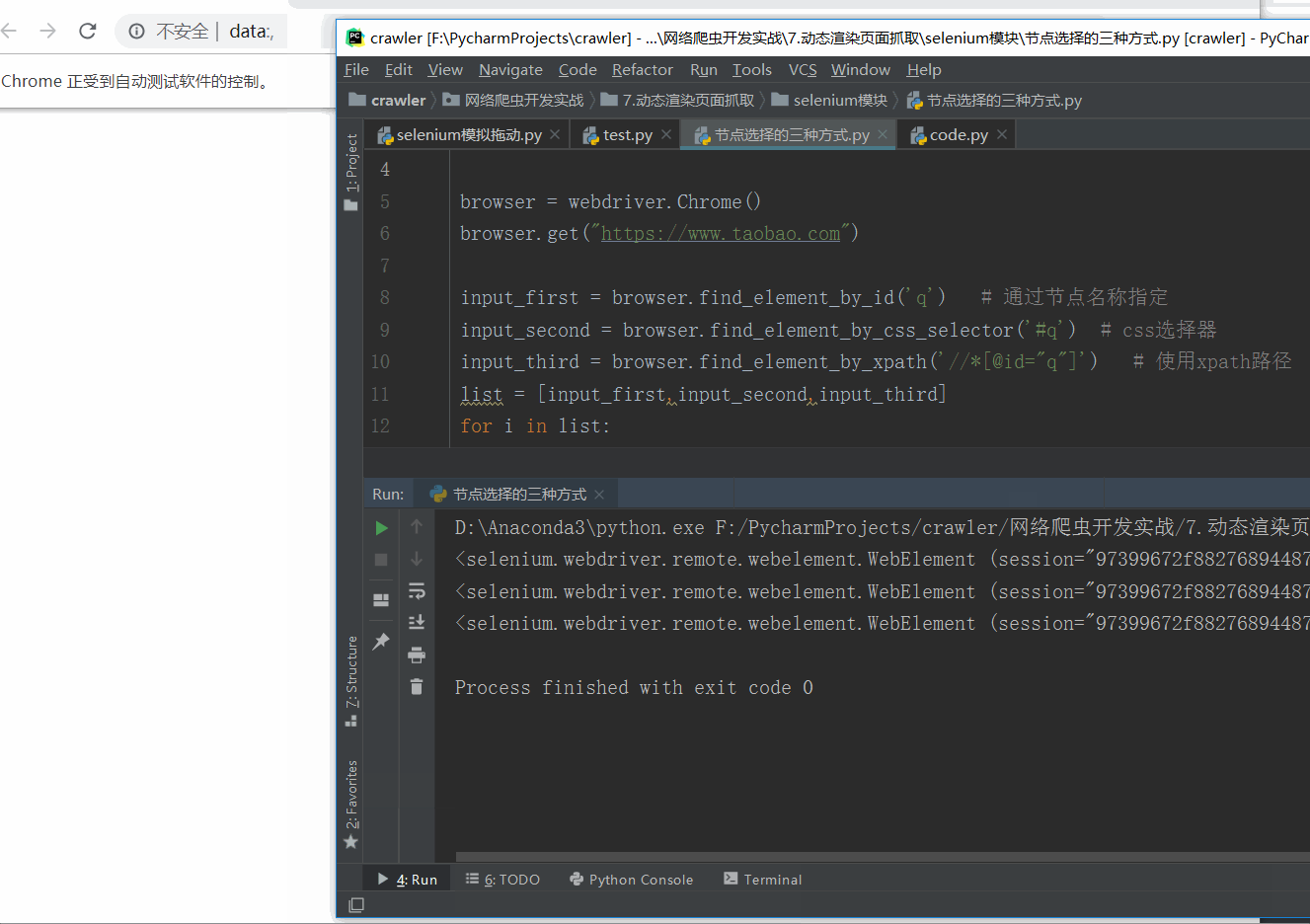
进入到淘宝页面中,通过selenium的节点选择,使我们的光标直接移动到了文本框中。
可以看到三个节点都是 WebElement 类型,是完全一致的。证明三种方法选择效果是一样的。

其他获取节点的方法:

这些API 都通过节点名称表明了它的作用。 我们就可以利用这些API,获取我们需要的节点了。
节点交互
Selenium 可以驱动浏览器来执行一些操作(文本输入和提交),也就是说我们可以让浏览器模拟执行一些动作,比较常见的用法有:输入文字用 send_keys() 方法,清空文字用 clear() 方法,另外还有按钮点击,用 click() 方法。
1 | from selenium import webdriver |
- 节点交互的方法基于WebElement对象
- 我们发现,每个搜素框都有对应的属性名、id值,我们需先利用find_element_by_id() 函数找到他(返回一个WebElement对象),然后传递交互方法。这样就实现了模拟浏览器的效果
- 使用send_keys 方法输入文字(这个方法挺常用的,例如selenium模拟登陆,我们可以输入用户名密码…)
- 其他交互动作也是由各个API封装好了,具体观看官方文档 : https://selenium-python-zh.readthedocs.io/en/latest/
动作链
在上面的实例中,一些交互动作都是针对某个节点执行的,比如输入框我们就调用它的输入文字和清空文字方法,按钮就调用它的点击方法,其实还有另外的一些操作它是没有特定的执行对象的,比如鼠标拖拽、键盘按键等操作。所以这些动作我们有另一种方式来执行,那就是动作链。 我们下面使用一个网站来测试 selenium 的动作链
1 | from selenium.webdriver import ActionChains # 动作链使用的类 |
效果演示:

- 搜的一下子,selenium 就出色的完成了拖动释放的操作,是不是很棒!
执行JavaScript语句
对于某些操作,SeleniumAPI 是没有提供的,如下拉进度条等,可以直接模拟运行 JavaScript,使用 execute_script() 方法即可实现。
1 | from selenium import webdriver |
效果演示:
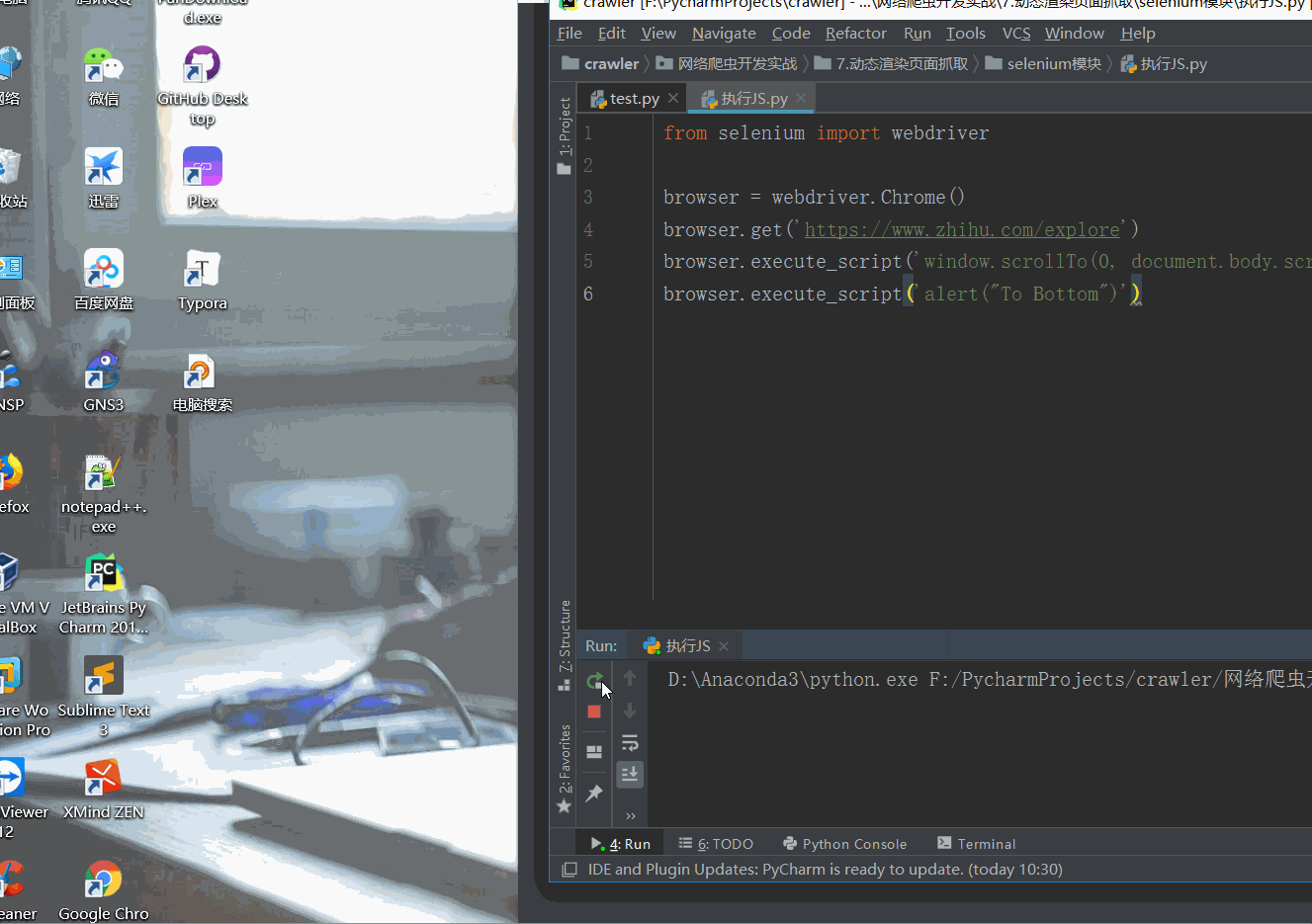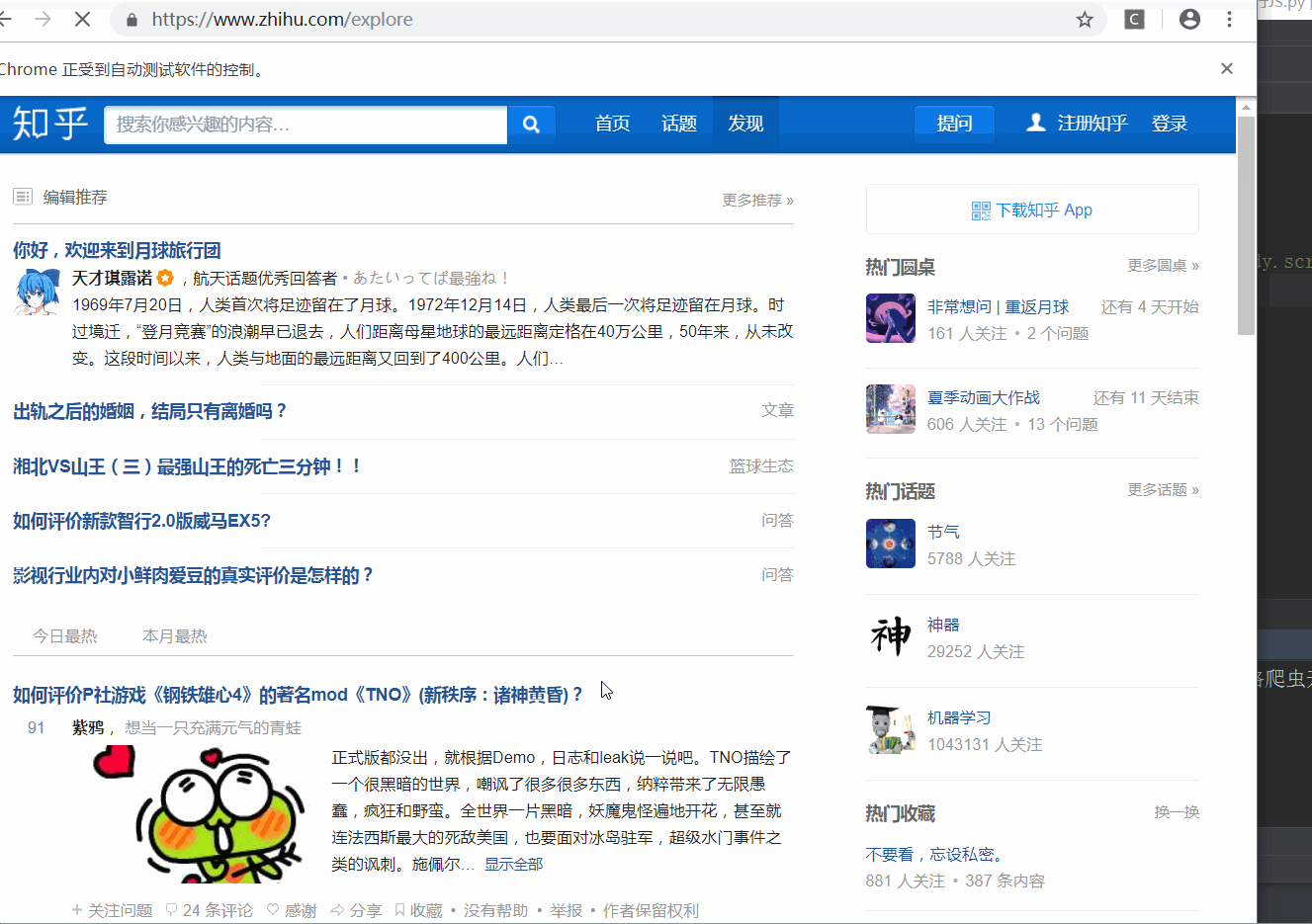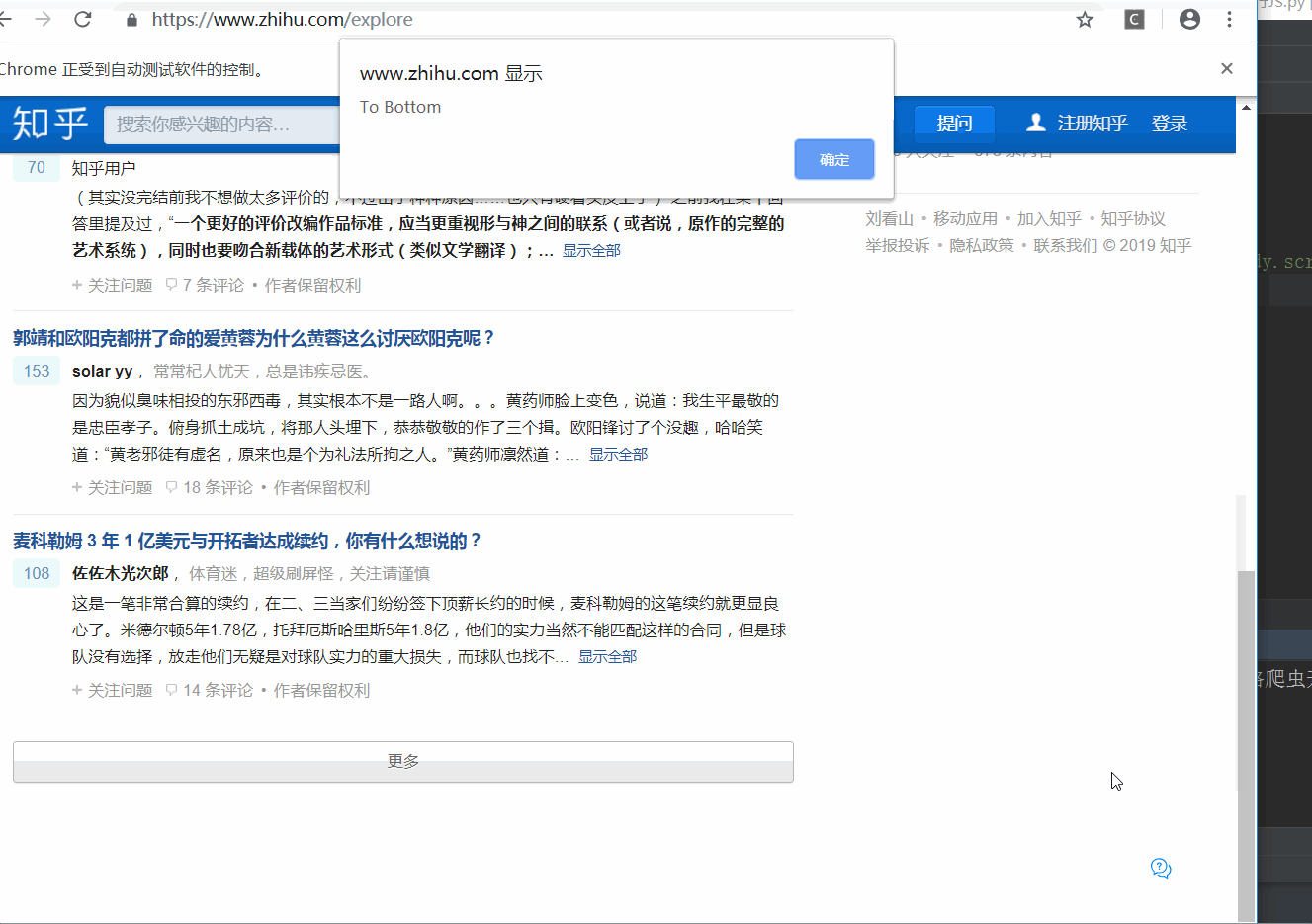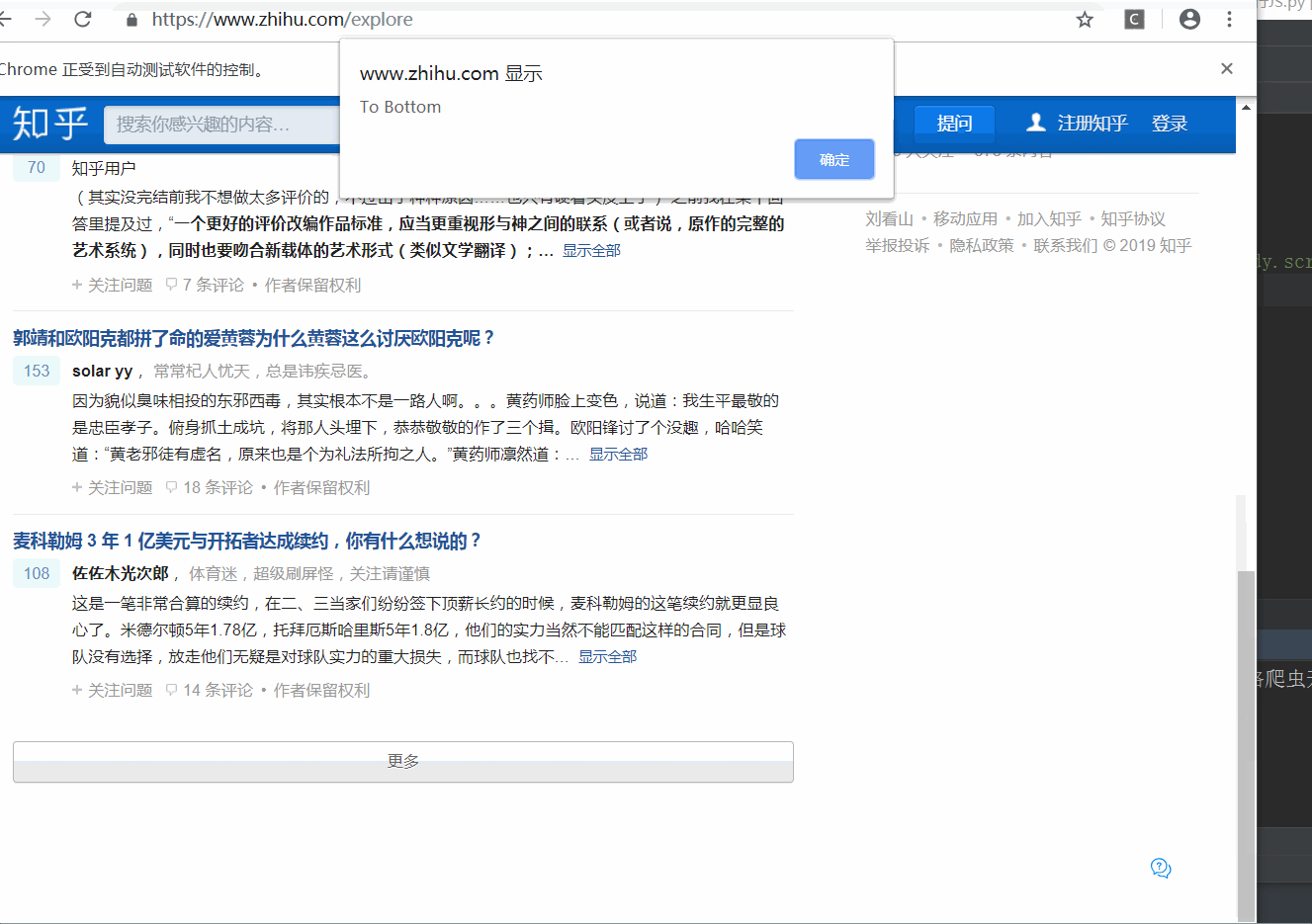
- 不单单上面举例的JS语句,还能实现打开选项卡等其他操作
获取节点信息
获取源代码
page_source 属性可以获取网页的源代码,获取源代码之后就可以使用解析库如正则、BeautifulSoup、PyQuery 等来提取信息了。不过既然 Selenium 已经提供了选择节点的方法,返回的是WebElement 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等等。这样的话我们就可以不用通过解析源代码来提取信息了。
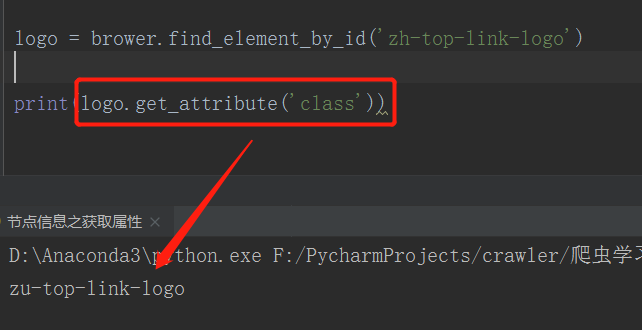
获取属性
使用find_element获取节点,基于WebElement对象 ,使用 get_attribute() 方法,传入想要获取的属性名,就可以得到它对应的值了。
获取文本值
原理同上,每个 WebEelement 节点都有 text 属性,我们可以通过直接调用这个属性就可以得到节点内部的文本信息了,就相当于 BeautifulSoup 的 get_text() 方法、PyQuery 的 text() 方法。
获取ID、相对位置、标签名、大小等信息
WebElement 节点还有一些其他的属性,比如 id 属性可以获取节点 id,location 可以获取该节点在页面中的相对位置,tag_name 可以获取标签名称,size 可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。
设置延时等待
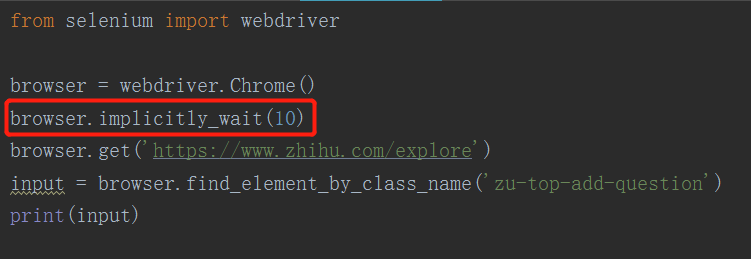
动态加载的页面需要时间等待页面上的所有元素都渲染完成,如果在没有渲染完成之前我们就switch_to_或者是find_elements_by_,那么就可能出现元素定位困难而且会产生错误信息
在 Selenium 中,get() 方法会在网页框架加载结束之后就结束执行,此时如果获取 page_source ,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求(Ajax发出请求和服务器响应网页渲染需要一定时间),我们在网页源代码中也不一定能成功获取到。
所以这里我们需要延时等待一定时间确保节点已经加载出来。在这里等待的方式有两种,一种隐式等待,一种显式等待。
隐式等待
当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0(固定的等待,如果已经加载出来,那么立即返回),如果超出设定时间后则抛出找不到节点的异常
显示等待
实际情况中,显示等待用的比较多,因为隐式等待的效果其实并没有那么好,因为我们只是规定了一个固定时间,而页面的加载时间是受到网络条件影响的。
所以在这里还有一种更合适的显式等待方法,它直接指定好要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,那就返回查找的节点,如果到了规定时间依然没有加载出该节点,则会抛出超时异常。并且还有一个好处——当页面加载很慢时,使用显示等待,等到需要操作的那个元素加载成功之后就直接操作这个元素,不需要等待其他元素的加载。
1 | from selenium import webdriver |
主要涉及到selenium.webdriver.support 模块下的expected_conditions类。 接着,我们首先引入了 Wait 这个对象,指定好最长等待时间,实例化出来一个 wait 等待对象。
然后调用它的 until() 方法。第一个参数传入要等待条件expected_conditions ,第二个参数传入对应的定位节点。比如在这里我们传入了 presence_of_element_located 这个条件,就代表当节点被加载出来时,条件被满足。其参数是节点的定位元组,也就是 class 为 “zu-top-add-question” 的节点搜索框。
所以这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点即搜索框成功加载出来了,那就返回该节点,如果超过10 秒还没有加载出来,那就抛出异常。
设置Cookies
使用 Selenium 还可以方便地对 Cookies 进行操作,例如获取、添加、删除 Cookies 等等。
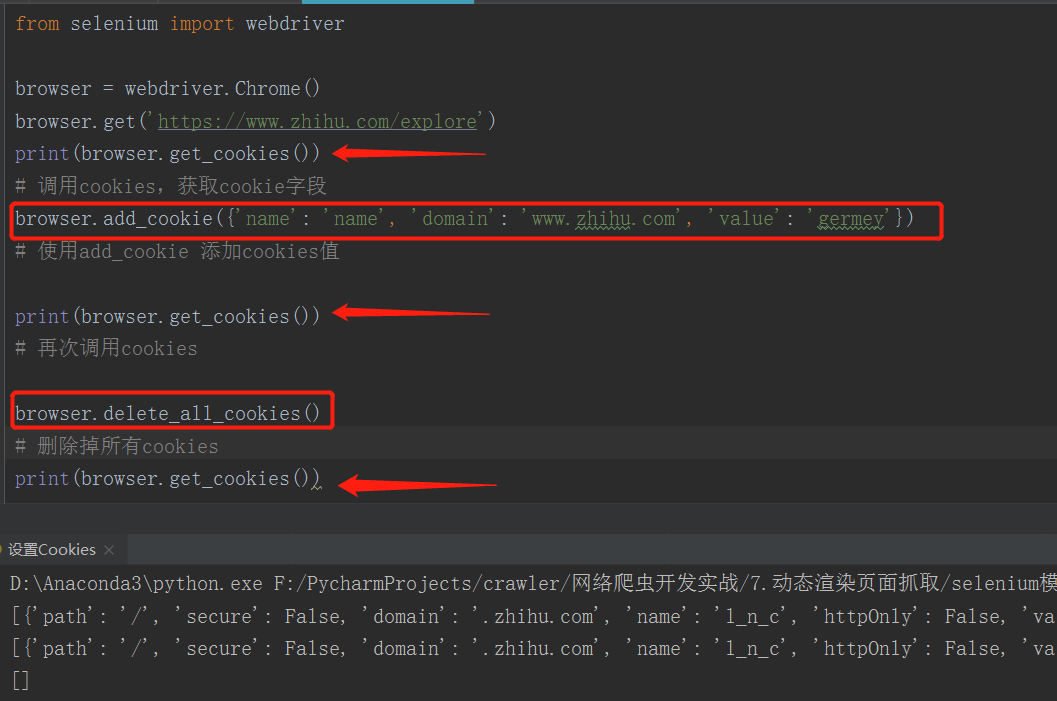
- 我们使用了三次 get_cookies() 来显示对Cookies 的一些操作,可以看到 第三次调用之前,我们对cookies进行删除,因此打印此出空列表
异常处理
在使用 Selenium 过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了,所以异常处理在程序中是十分重要的。我们可以使用 try except 语句来捕获各种异常。
1 | from selenium import webdriver |
- 异常处理有利于我们后期的排错,也有利于爬取过程中一些错误的处理,一个完整的爬虫脚本应该含括异常处理。
我们把 selenium 大概的介绍完了! 有没有像我一样,一接触selenium 就被他高明的抓取手段迷住了呢?哈哈